[論文レビュー] A Note on Normalized Emergence Timing (in Pythia Language Model Evaluations)
この論文は、同一データ順で訓練された公開可能な LLM の Pythia 系を紹介し、訓練ダイナミクス、スケーリング効果、バイアス、メモリ化、用語頻度の影響に関するケーススタディを分析します。
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at \url{https://github.com/EleutherAI/pythia}.
研究の動機と目的
- 標準化された公開可能なモデルスイートを提供することで、巨大言語モデルに関する科学的研究を促進する。
- 訓練データの順序、デデュプリケーション、およびモデルサイズが学習ダイナミクスとバイアスに与える影響を調査する。
- 訓練の進行に伴う下流タスク性能に対する前学習時の用語頻度の役割を検討する。
提案手法
- 同一データ順で訓練し、公開チェックポイントを各モデルあたり154個用意した、8つのモデルサイズ(70M〜12B パラメータ)のスイートを提供する。
- Pile およびデデュプリケーション済みの Pile の上でスイートを2コピー訓練してデータの影響を研究する。
- 解釈性と効率のため、結合されていない埋め込み行列を用いた密な並列アテンションと回転埋め込みを使用する。
- スケーラビリティのため、GPT-NeoX フレームワーク、ZeRO、データ/テンソル並列、Flash Attention を用いて大規模バッチサイズ(1024)を適用する。
- 8 つのベンチマークで Language Model Evaluation Harness を用いて評価し、OPT/BLOOM のベースラインと比較する。
- 全モデル、チェックポイント、評価コードを Apache 2.0 の下で公開し、完全な再現性を確保する。
実験結果
リサーチクエスチョン
- RQ1訓練データの順序、デデュプリケーションが、スケールごとのモデルの性能と memorization にどのように影響するか。
- RQ2訓練中の前学習時の用語頻度がタスク性能に与える影響は何か。
- RQ3並列アテンションとMLP 層のアーキテクチャ選択は、小規模モデルと大規模モデルの性能に影響を与えるか。
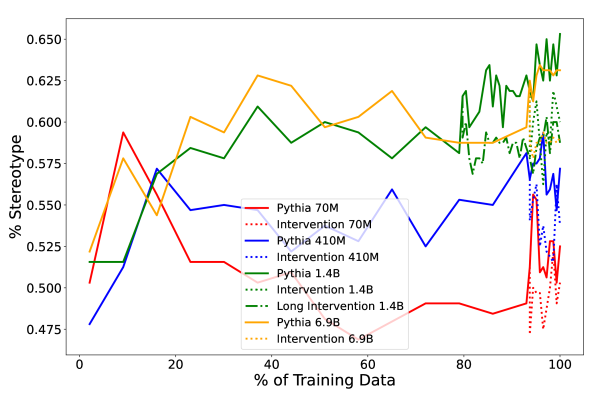
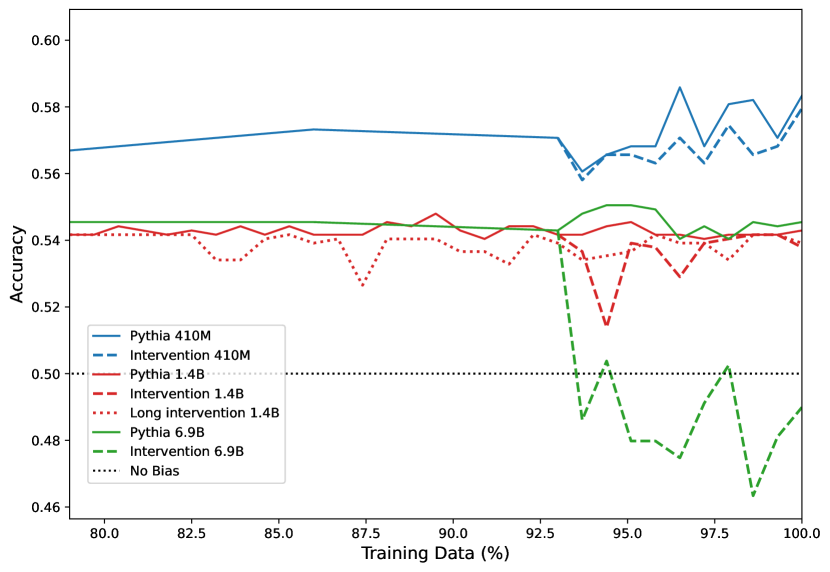
- RQ4 pronoun frequency の介入が、モデルサイズ別の下流のバイアス測定にどのように影響するか。
主な発見
- デデュプリケーションは、Pythia 系の言語モデリングにおける明確な性能利点を示さない。
- 並列アテンション + MLP によって、等価トークン数・等価パラメータ性能がスケール間で達成され、いくつかの先行研究の主張とは異なる。
- BLOOM における多言語性の呪いは、ベンチマークに依存して最小限で不規則であるため、多様なタスクで再評価の余地がある。
- ポアソン点過程は memorization のタイミングを適切にモデル化し、訓練順序が memorized な系列への影響を限定的であることを示唆する。
- 約 65,000 訓練ステップ(訓練の 45% 付近)で重要な相変化が発生し、大規模モデル(2.8B 以上)ではタスクの正確さと前学習用語頻度との相関が現れる。
- 最後の 7% または 21% の訓練での代名詞頻度介入は、ベースラインタスクのパープレキシティを大きく崩さずに、対象となるベンチマークで性別バイアスを低減する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。