[論文レビュー] A Pathway Towards Responsible AI Generated Content
この論文はAI生成コンテンツ(AIGC)の8つの主要リスクを概観し、プライバシー、偏見、知的財産、頑健性、オープンソース、乱用、同意/クレジット、環境問題に対処することで責任あるAIGCを開発する方向性を示す。
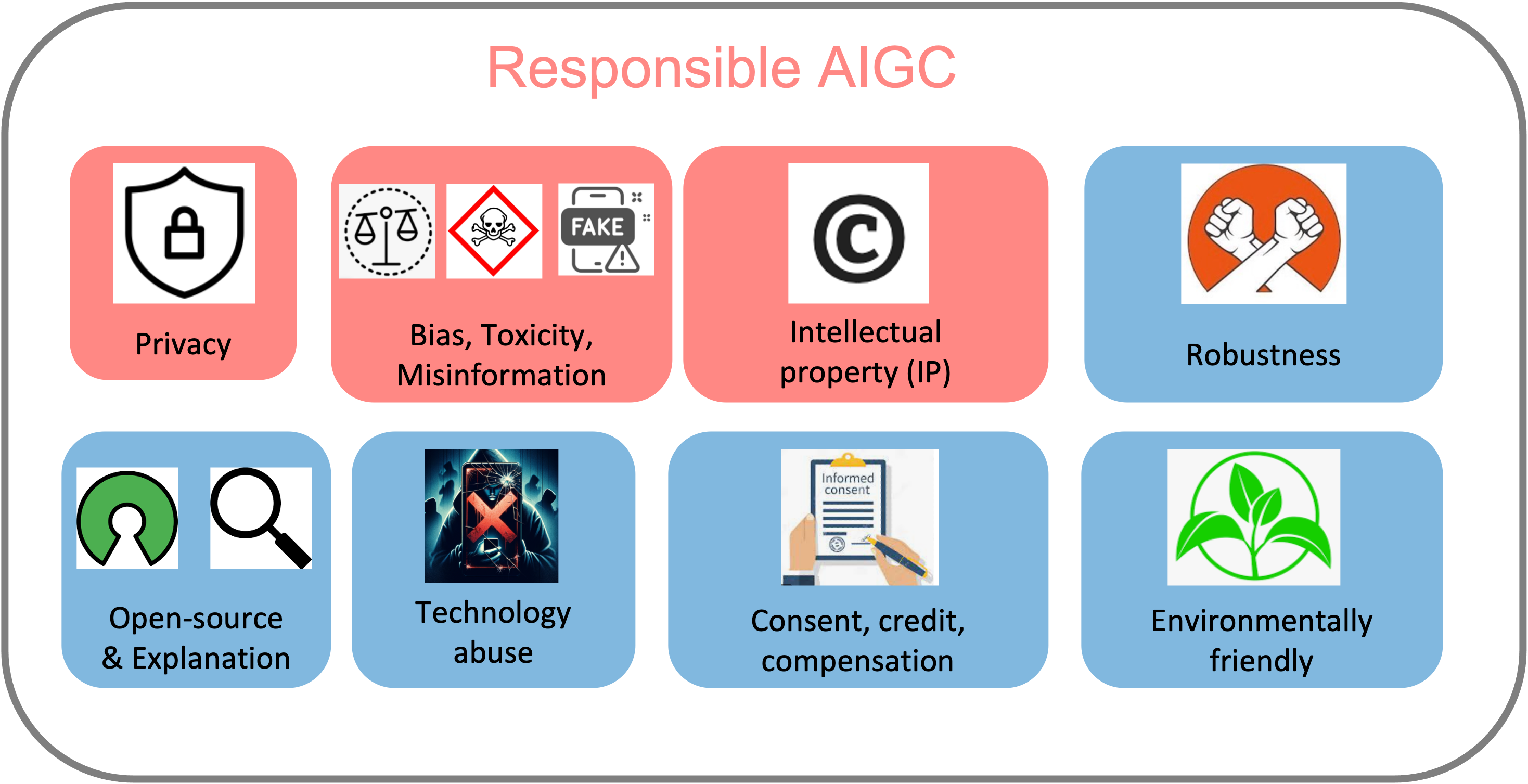
AI Generated Content (AIGC) has received tremendous attention within the past few years, with content generated in the format of image, text, audio, video, etc. Meanwhile, AIGC has become a double-edged sword and recently received much criticism regarding its responsible usage. In this article, we focus on 8 main concerns that may hinder the healthy development and deployment of AIGC in practice, including risks from (1) privacy; (2) bias, toxicity, misinformation; (3) intellectual property (IP); (4) robustness; (5) open source and explanation; (6) technology abuse; (7) consent, credit, and compensation; (8) environment. Additionally, we provide insights into the promising directions for tackling these risks while constructing generative models, enabling AIGC to be used more responsibly to truly benefit society.
研究の動機と目的
- 責任あるAIGC導入を妨げる8つの主要懸念を特定する(プライバシー、偏見/毒性/誤情報、IP、頑健性、オープンソースと説明性、技術の乱用、同意/クレジット/補償、環境)。
- これらのリスクを構築・展開において緩和するための洞察と方向性を提供する。
- 基盤モデルがAIGCを可能にする仕組みと、リスクがモダリティ間(テキスト、画像、動画、音声)にどう伝播するかを論じる。
提案手法
- AIGCリスクに関する既存の文献と産業実践をレビューし、統合する。
- リスクカテゴリーを具体的な緩和戦略(データ選別、フィルタリング、ウォーターマーク、アクセス制御、ガバナンス)に対応付ける。
- ライフサイクル全体を通じた責任あるAIGCに向けた政策・技術・社会的アプローチの議論を提案する。
- 代表的なモデルとデータセットを取り上げ、リスク領域を説明する(プライバシー漏洩、データセットの偏り、 memorization、IP懸念)。
実験結果
リサーチクエスチョン
- RQ1AI Generated Content に関連する主なリスクは何か(プライバシー、偏見/毒性/誤情報、IP、頑健性、オープンソース、乱用、同意/クレジット、環境?)
- RQ2これらのリスクを緩和しつつAIGCの有益な利用を可能にする方向性と戦略は何か?
- RQ3基盤モデルはリスクにどのように寄与し、リスク緩和をモデル設計と展開にどう組み込むべきか?
主な発見
- AIGCはプライバシー、偏見、誤情報、IP、頑健性、オープン性、乱用、環境影響にわたる相互に関連したリスクを抱える。
- 緩和アプローチにはデータフィルタリング、デュプリケーション排除、ウォーターマーキング、出力フィルタリング、モデルの再調整、ガバナンス機構を含む。
- コンテンツの所有権とIP帰属は法的に未解決のままで、DMCA takedownポリシー、ウォーターミーキング、帰属の検討といった実践を促している。
- 幻覚と誤情報は訓練データの品質、過適合、プロンプト設計に起因する。定期的なデータ更新とユーザーフィードバックで低減可能。
- オープンソースの透明性には賛否がある。透明性は説明を助ける一方で、悪用や競争上の懸念リスクも高める。
- データ提供者がAIGCのトレーニングデータから利益を得られるよう、ガバナンス・同意・補償モデルが必要。
- 大規模モデルの環境コストは、より小型化したモデルや効率性に焦点を当てた研究を促す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。