[論文レビュー] A Perspective on Explainable Artificial Intelligence Methods: SHAP and LIME
本コメントは、表形式データに対する XAI 手法としての SHAP と LIME を分析し、それらの仮定、長所・短所を論じ、適切な使用と解釈のための推奨を提供する。
eXplainable artificial intelligence (XAI) methods have emerged to convert the black box of machine learning (ML) models into a more digestible form. These methods help to communicate how the model works with the aim of making ML models more transparent and increasing the trust of end-users into their output. SHapley Additive exPlanations (SHAP) and Local Interpretable Model Agnostic Explanation (LIME) are two widely used XAI methods, particularly with tabular data. In this perspective piece, we discuss the way the explainability metrics of these two methods are generated and propose a framework for interpretation of their outputs, highlighting their weaknesses and strengths. Specifically, we discuss their outcomes in terms of model-dependency and in the presence of collinearity among the features, relying on a case study from the biomedical domain (classification of individuals with or without myocardial infarction). The results indicate that SHAP and LIME are highly affected by the adopted ML model and feature collinearity, raising a note of caution on their usage and interpretation.
研究の動機と目的
- 高リスク領域における XAI の動機とブラックボックスモデルを解明する必要性を説明する。
- SHAP と LIME がどのように説明を生成し、何を表すと主張するのかを明確にする。
- SHAP と LIME の弱点と長所を特定し、前提条件や潜在的な落とし穴を含めて検討する。
- 実務における SHAP および LIME の解釈と適切な使用を改善するための推奨を提供する。
提案手法
- SHAP を、ゲーム理論と特徴量寄与に基づくモデル非依存のポストホック手法として説明する。
- Kernel SHAP を、多数の特徴量を扱うための近似として説明する。
- SHAP の説明はモデルに依存し、特徴量の独立性の仮定や多重共線性の影響を受け得ることを説明する。
- LIME を、単一のインスタンスに対して複雑なモデルを局所線形モデルに変換するモデル非依存の局所解釈器として説明する。
- LIME もモデル依存であり、いくつかのモデルで非線形関係を誤って表現する可能性がある点を強調する。
- エンドユーザーが非専門家である場合や共線性のある特徴量を扱う場合の解釈性の課題について論じる。
- SHAP の出力を平易な言葉で報告する際の指針と、特徴リストを評価する安定性指標として NMR のような指標を用いることを提案する。
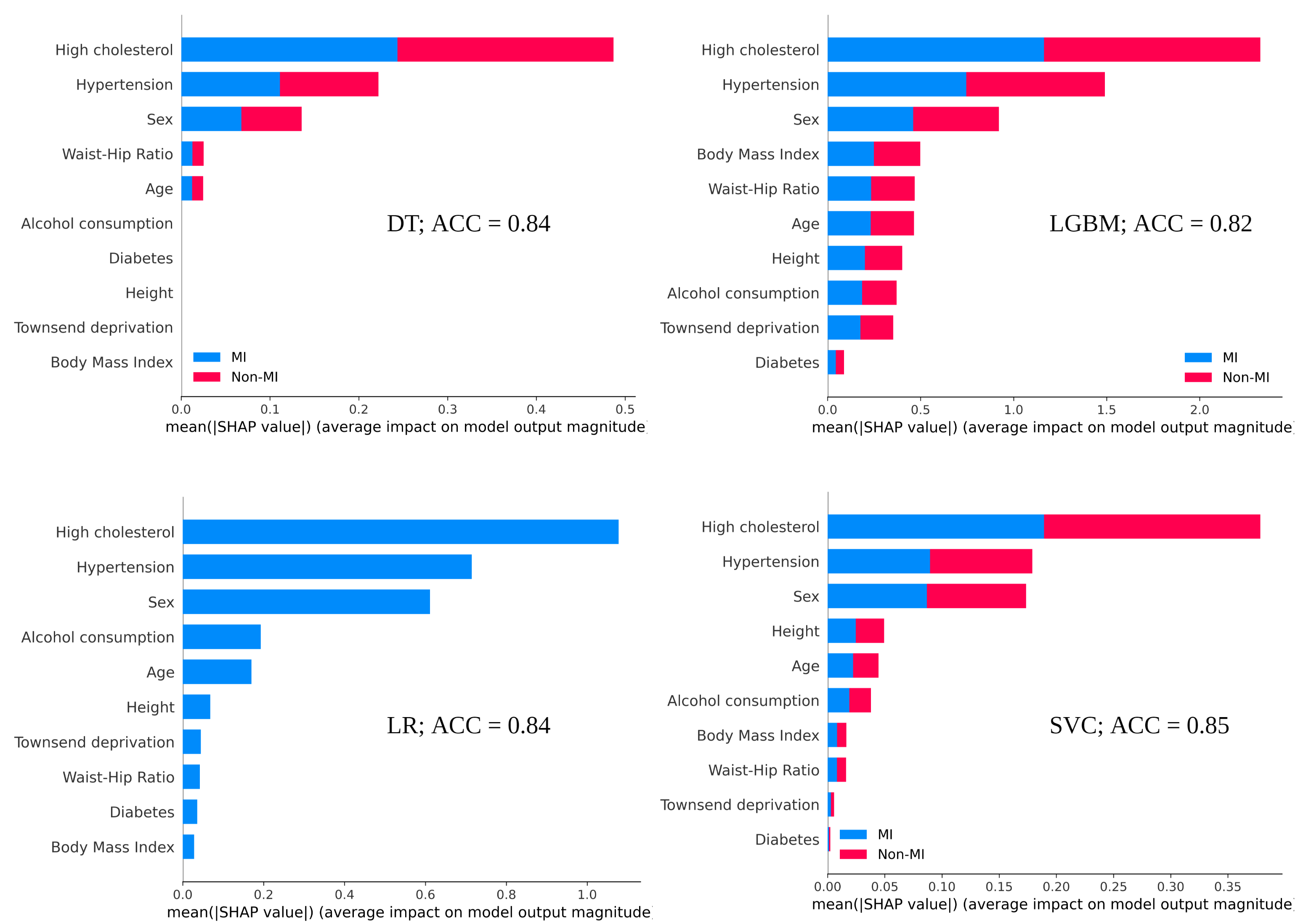
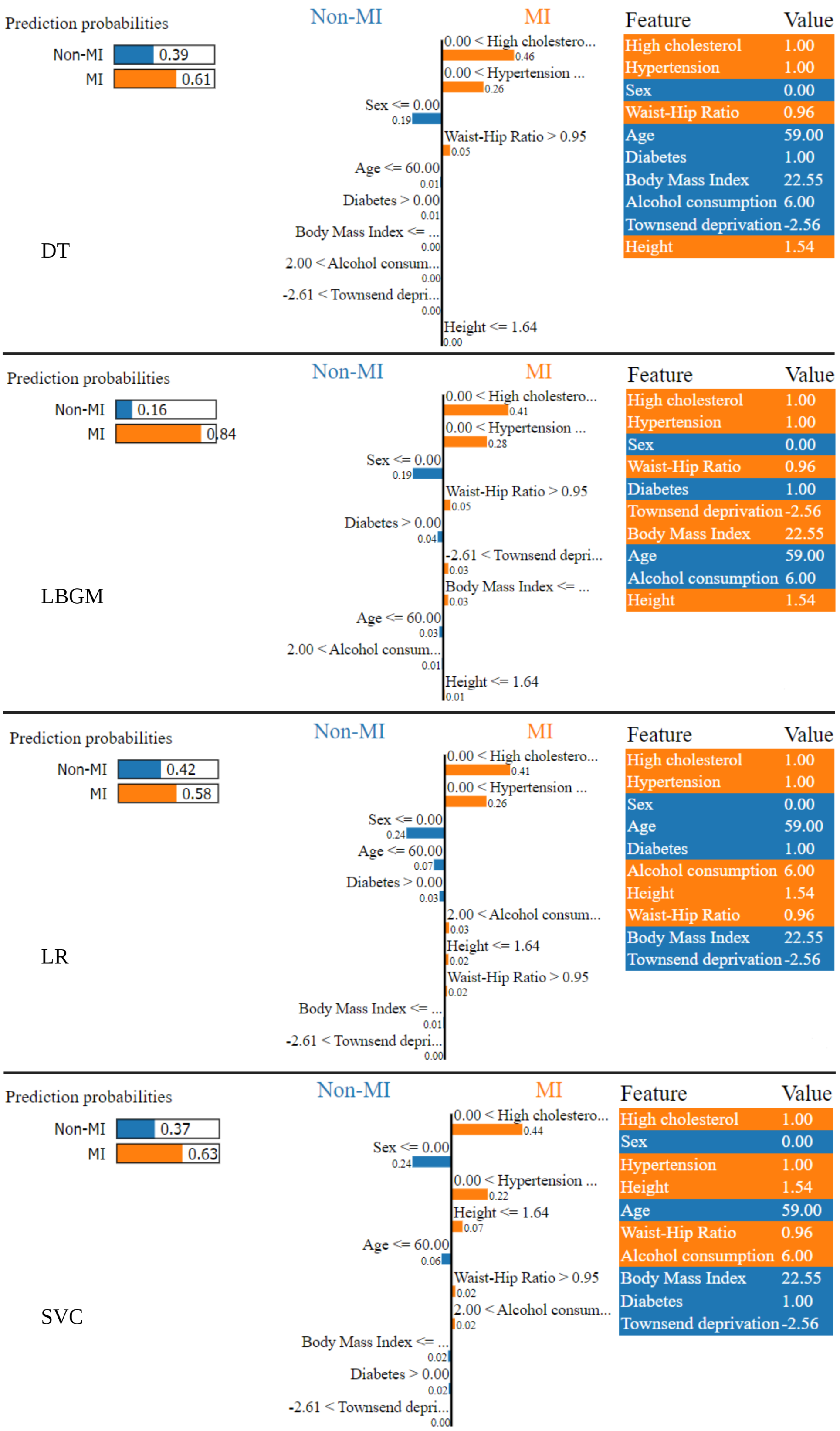
実験結果
リサーチクエスチョン
- RQ1モデル予測を説明する際の SHAP および LIME の核心的な前提条件は何か?
- RQ2表形式データに対する SHAP および LIME の実用的な長所と限界は何か?
- RQ3研究者とエンドユーザーは、誤解を避けるために SHAP および LIME の出力をどのように解釈すべきか?
- RQ4SHAP および LIME の説明の適切な使用と報告を改善するためにはどのような推奨があるか?
主な発見
- SHAP の結果は選択されたモデルに依存し、異なるモデルは異なる特徴量重要度の順序を生み出すことがある。
- SHAP は特徴量の独立性を前提とするが、多重共線性の存在下で偏りのある、あるいは非現実的な説明につながることがある。
- SHAP は偏った分類器によってバイアスを受ける可能性があり、基底の偏りを反映しない説明を生み出すことがある。
- LIME は複雑なモデルを局所線形モデルで近似して局所的な予測を説明するが、非線形な関係を見逃すことがある。
- LIME の説明は特定のインスタンスに局所的であり、モデル全体に一般化されないことがある;解釈は特徴量の共線性の影響を受けることがある。
- どちらの手法も慎重なコミュニケーションが必要で、出力を単純化し、安定性指標を用いることで有益になる可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。