[論文レビュー] A Practical Mixed Precision Algorithm for Post-Training Quantization
この論文は、SQNRを用いて層ごとの感度リストを構築し、Paretoフロンティアの貪欲探索でビット幅を割り当て、ハードウェアと精度の予算内で、AdaRoundの統合を用いて低ビットの性能を向上させる、トレーニングデータなしの事後量子化(post-training quantization)を提案する。
Neural network quantization is frequently used to optimize model size, latency and power consumption for on-device deployment of neural networks. In many cases, a target bit-width is set for an entire network, meaning every layer get quantized to the same number of bits. However, for many networks some layers are significantly more robust to quantization noise than others, leaving an important axis of improvement unused. As many hardware solutions provide multiple different bit-width settings, mixed-precision quantization has emerged as a promising solution to find a better performance-efficiency trade-off than homogeneous quantization. However, most existing mixed precision algorithms are rather difficult to use for practitioners as they require access to the training data, have many hyper-parameters to tune or even depend on end-to-end retraining of the entire model. In this work, we present a simple post-training mixed precision algorithm that only requires a small unlabeled calibration dataset to automatically select suitable bit-widths for each layer for desirable on-device performance. Our algorithm requires no hyper-parameter tuning, is robust to data variation and takes into account practical hardware deployment constraints making it a great candidate for practical use. We experimentally validate our proposed method on several computer vision tasks, natural language processing tasks and many different networks, and show that we can find mixed precision networks that provide a better trade-off between accuracy and efficiency than their homogeneous bit-width equivalents.
研究の動機と目的
- レイヤごとの量子化耐性の頑健性を活用して、均一なビット幅よりもデバイス上の性能を改善する動機付け。
- 最小データとハイパーパラメータ調整なしで機能するポスト量子化手法の開発。
- 実用的なハードウェア制約を量子化器グループと効率指標を通じて組み込む。
- 較正データの変動やドメイン外入力に対して頑健性を示す。
- 提案手法が同質量子化よりも、さまざまなモデルにおいて精度と効率のトレードオフを改善することを示す。
提案手法
- Phase 1では、各レイヤの異なる量子化オプションでネットワーク損失を測定し、感度指標としてSQNRを用いて層ごとの感度リストを作成する。
- Phase 2は最高精度の量子化から開始し、感度リストに導かれてビット幅を反復的に低下させ、Paretoフロンティア貪欲探索を介して事前定義された性能予算を達成する。
- 量子化器グループを導入して、グループ内で共有操作が一貫した精度を使用するよう、ハードウェアに課せられた依存関係を強制する。
- AdaRoundを統合して低ビット量子化の性能を向上させ、Phase 1の感度測定でAdaRounded重みを使用し、ビット幅構成間でこれらの重みを接合する。
- 探索を二分探索と補間戦略で加速し、実行時間を短縮しつつパレート曲線のモノトニック性を活用する。
- Phase 1はラベルなしで動作し、少量の較正データを許容しつつデータ変動に対して頑健でいられる。
実験結果
リサーチクエスチョン
- RQ1ポストトレーニング混合精度量子化は、CVとNLPタスクのさまざまなアーキテクチャに対して固定精度量子化より上回ることができるか。
- RQ2較正データの変動やドメイン外データを感度推定に使用した場合の手法の頑健性はどの程度か。
- RQ3量子化器グルーピングなどのハードウェア制約は、実現可能な混合精度構成と性能にどのように影響するか。
- RQ4AdaRoundを混合精度パイプラインに統合すると、特に非常に低いビット幅で精度が改善されるか。
主な発見
- 提案されたPTQ MP手法は、Mobilenetv3、Deeplabv3、Efficientnet、BERT、ViTなどの複数モデルにおいて、同質ビット幅ネットワークよりも優れた精度-効率のトレードオフを提供する混合精度構成を見つける。
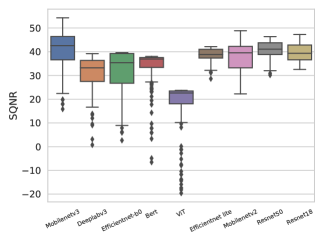
- SQNRベースの層ごとの感度リストは、較正データの変動と較正画像数に対して頑健であり、精度ベースの感度に対する Kendall Tau 相関よりも有利である。
- AdaRoundを混合精度パイプラインと統合することで、低ビット(8未満)の量子化性能が向上し、固定精度のAdaRoundを上回ることがある。
- Phase 2の実行時間は、二分探索と補間戦略を用いて改善され、探索複雑さを低減しつつ良好な Pareto 曲線を維持する。
- 本手法は、W4A8、W8A8、W8A16 などのさまざまなビット幅候補集合で効果的であり、低ビット領域を拡張しても適用可能である(例:W4A4、W6A6 など)。
- Phase 1と2は、タスクデータがほとんどない、あるいは全くない状態でも動作可能で、ドメイン外やプライバシー保護された較正シナリオを実現する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。