[論文レビュー] A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models
トランスフォーマー言語モデルの機械的解釈性(MI)に関する総合的な調査で、基本オブジェクト、技術、評価、発見、および初心者向けロードマップを概説する。特徴、回路、普遍性、そして将来の方向性を強調する。
Mechanistic interpretability (MI) is an emerging sub-field of interpretability that seeks to understand a neural network model by reverse-engineering its internal computations. Recently, MI has garnered significant attention for interpreting transformer-based language models (LMs), resulting in many novel insights yet introducing new challenges. However, there has not been work that comprehensively reviews these insights and challenges, particularly as a guide for newcomers to this field. To fill this gap, we provide a comprehensive survey from a task-centric perspective, organizing the taxonomy of MI research around specific research questions or tasks. We outline the fundamental objects of study in MI, along with the techniques, evaluation methods, and key findings for each task in the taxonomy. In particular, we present a task-centric taxonomy as a roadmap for beginners to navigate the field by helping them quickly identify impactful problems in which they are most interested and leverage MI for their benefit. Finally, we discuss the current gaps in the field and suggest potential future directions for MI research.
研究の動機と目的
- MIの基本オブジェクト(特徴、回路、普遍性)とそれらがトランスフォーマー LM にどのように関連するかを調査する。
- MI の技術を要約する(ロジットレンズ、プロービング、SAE、可視化、自動特徴説明、ノックアウト/アブレーション、CMA)。
- 忠実度、包括性、最小性、妥当性といった評価基準を議論し、それらがどのように適用されるか。
- MI における特徴と回路の研究を初心者にも分かるロードマップを提供する。
- 主要な発見と応用を強調し、LM の MI におけるギャップと将来の方向性を特定する。
提案手法
- 特徴、回路、普遍性を含むMI研究の分類を提示する。
- コアな MI 手法を説明する:ロジットレンズ、プロービング、スパースオートエンコーダ(SAE)、可視化、自動特徴説明、ノックアウト/アブレーション、因果介在分析(CMA)。
- 評価指標を説明する:忠実度、包括性、最小性、妥当性。
- 特徴と回路研究の手順を詳述する初心者向けロードマップを提供する。
- 特徴、回路、普遍性、モデル能力、学習ダイナミクス、応用に関する研究間の知見を統合する。
実験結果
リサーチクエスチョン
- RQ1トランスフォーマー LM の機械的解釈性を定義する基本的なオブジェクト(特徴、回路、普遍性)は何か?
- RQ2これらのオブジェクトを研究するためにどのような技術が用いられ、結果はどのように評価されるか?
- RQ3MI研究は特徴、回路、普遍性、LMの能力についてどのような発見を生み出しているか?
- RQ4初心者はMI研究をどのように体系的に実施できるか、現在のギャップと将来の方向性は何か?
主な発見
- LM の特徴はしばしば多義的であり、重ね合わせを示すことがあり、単一意味のマッピングを難しくする。
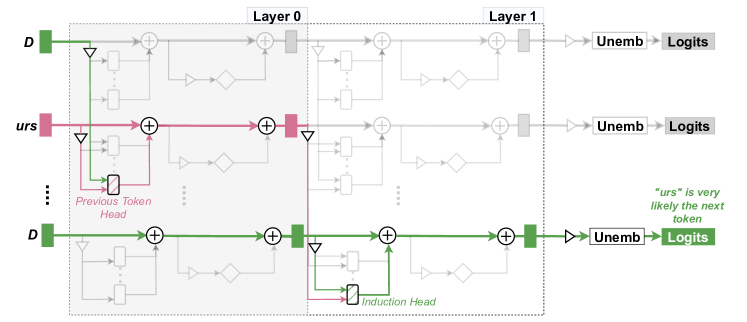
- 回路は、文脈内学習、IOI、算術などのLMの挙動が、特殊なコンポーネントを介して実装され、タスク間で再利用されることを示す。
- 特徴と回路の普遍性は混在しており、モデルサイズ、初期化、訓練に依存する。いくつかのコンポーネントは共有される一方、他はモデル間で異なる。
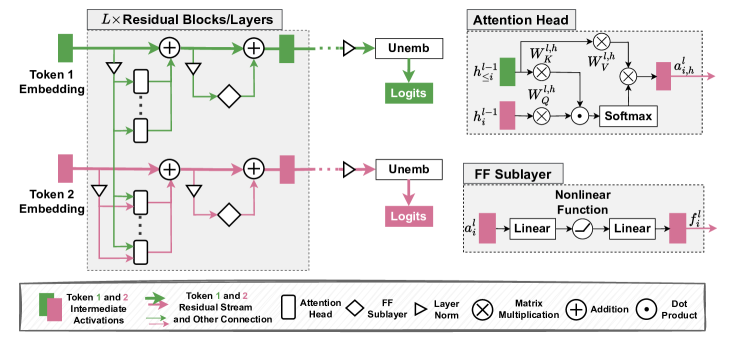
- Transformer のコンポーネント(残差ストリーム、MHA、FF)は異なる役割を持ち、ヘッドはコピー抑制、誘導、知識格納などの特化した機能を示す。
- MI 研究は能力とダイナミクスの理解に明確な進展を示しているが、スケーラビリティ、一般化、安全性に関する課題はまだ未解決のままである。
- 初心者向けのワークフローとロードマップが提供されており、新しい研究者がLM にMI 手法を適用するのを支援する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。