[論文レビュー] A Review of Deep Learning Techniques for Speech Processing
深層学習アーキテクチャ(RNN、CNN、Transformers、Conformers、拡散モデル、GNN)とそれらの音声タスク、データセット、将来方向性への総合的な調査。
The field of speech processing has undergone a transformative shift with the advent of deep learning. The use of multiple processing layers has enabled the creation of models capable of extracting intricate features from speech data. This development has paved the way for unparalleled advancements in speech recognition, text-to-speech synthesis, automatic speech recognition, and emotion recognition, propelling the performance of these tasks to unprecedented heights. The power of deep learning techniques has opened up new avenues for research and innovation in the field of speech processing, with far-reaching implications for a range of industries and applications. This review paper provides a comprehensive overview of the key deep learning models and their applications in speech-processing tasks. We begin by tracing the evolution of speech processing research, from early approaches, such as MFCC and HMM, to more recent advances in deep learning architectures, such as CNNs, RNNs, transformers, conformers, and diffusion models. We categorize the approaches and compare their strengths and weaknesses for solving speech-processing tasks. Furthermore, we extensively cover various speech-processing tasks, datasets, and benchmarks used in the literature and describe how different deep-learning networks have been utilized to tackle these tasks. Additionally, we discuss the challenges and future directions of deep learning in speech processing, including the need for more parameter-efficient, interpretable models and the potential of deep learning for multimodal speech processing. By examining the field's evolution, comparing and contrasting different approaches, and highlighting future directions and challenges, we hope to inspire further research in this exciting and rapidly advancing field.
研究の動機と目的
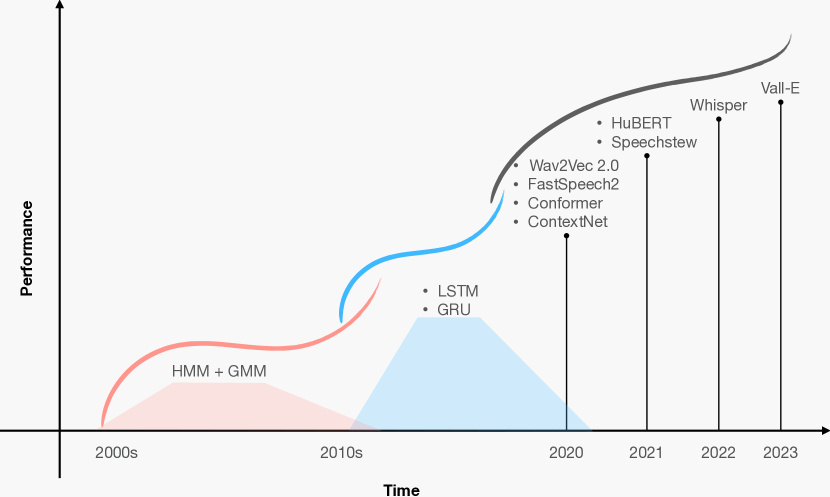
- 従来の(MFCC、HMM)アプローチから現代の深層学習モデルへの音声処理の進化を辿る。
- 音声タスクにおける深層学習アーキテクチャ(RNNs、CNNs、Transformers、Conformers、diffusion models、GNNs)の分類と比較。
- 表現学習(教師あり、教師なし、半教師あり、自己教師あり)の調査と音声処理における役割。
- 広範な音声処理タスク(ASR、合成、話者認識、ダイアライゼーション、翻訳、強化、マルチモーダル処理)と関連データセット/ベンチマークのレビュー。
- 転移学習手法(ドメイン適応、メタ学習、パラメータ効率的手法)を議論し、将来の研究方針を概説。
提案手法
- 音声処理で用いられる深層学習アーキテクチャの広範な分類法を提供する(RNNs、CNNs、Transformers、Conformers、シーケンス・ツー・シーケンスモデル、強化学習、グラフニューラルネットワーク、拡散モデル)。
- 音声表現学習パラダイム(教師あり、教師なし、半教師あり、自己教師あり)の説明と性能への影響。
- 主要な音声処理タスクとそれらに対処する深層学習アプローチの調査(ASR、合成、話者認識、ダイアライゼーション、翻訳、強化、VAD、品質評価、分離、SLU、視聴覚処理)。
- 音声処理に関連する高度な転移学習技術を議論する(ドメイン適応、メタ学習、パラメータ効率的転移学習)。
- データ効率、解釈容易性、堅牢性などの課題を強調し、潜在的な将来の方向性として(マルチモーダル音声処理、効率性、一般化)を示す。
実験結果
リサーチクエスチョン
- RQ1コアな音声タスクにおける主要な深層学習アーキテクチャの相対的な利点と制約は何か?
- RQ2データセットとベンチマークは音声処理タスクの進展にどのように影響してきたか?
- RQ3表現学習(教師あり対自己教師あり)の役割は、音声タスクの性能向上においてどうであるか?
- RQ4展開を制限する課題(データ効率、解釈容易性、堅牢性)は何か、最も有望な将来の方向性はどれか?
- RQ5転移学習手法は、ドメインやモダリティを超えた音声処理の進歩をどのように促進できるか?
主な発見
- 深層学習は、認識、合成、話者分析などの音声タスクにおいて、従来の手法と比較して大きな進歩をもたらした。
- エンドツーエンドのRNN、CNN、Transformerベースのモデルが現代の音声システムの中心となり、しばしHMMベースのパイプラインを上回ることが多い。
- 自己教師ありおよび半教師ありの表現は、ラベル付きデータの要件を削減し、堅牢性を向上させるためにますます活用されている。
- マルチモーダルアプローチ(音声-視覚)は、特に音声活動検出と認識において厳しい環境で有望である。
- 転移学習、ドメイン適応やパラメータ効率的手法を含む、それはドメイン横断の音声処理タスクに有効である。
- 研究分野は、性能と計算効率および解釈性のバランスを取るアーキテクチャの探求を続けている。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。