[論文レビュー] A Riemannian Network for SPD Matrix Learning
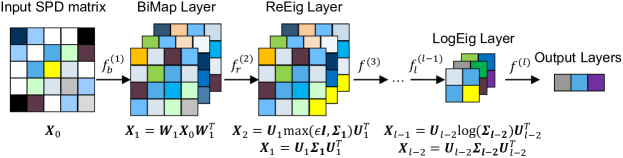
SPDNet を紹介する。BiMap、ReEig、LogEig 層を用いて SPD 行列の非線形表現を学習し、Stiefel 多様体上の Riemannian SGD で訓練して SPD 構造を保持する深層ネットワーク。
Symmetric Positive Definite (SPD) matrix learning methods have become popular in many image and video processing tasks, thanks to their ability to learn appropriate statistical representations while respecting Riemannian geometry of underlying SPD manifolds. In this paper we build a Riemannian network architecture to open up a new direction of SPD matrix non-linear learning in a deep model. In particular, we devise bilinear mapping layers to transform input SPD matrices to more desirable SPD matrices, exploit eigenvalue rectification layers to apply a non-linear activation function to the new SPD matrices, and design an eigenvalue logarithm layer to perform Riemannian computing on the resulting SPD matrices for regular output layers. For training the proposed deep network, we exploit a new backpropagation with a variant of stochastic gradient descent on Stiefel manifolds to update the structured connection weights and the involved SPD matrix data. We show through experiments that the proposed SPD matrix network can be simply trained and outperform existing SPD matrix learning and state-of-the-art methods in three typical visual classification tasks.
研究の動機と目的
- Symmetric Positive Definite (SPD) 行列上でのリーマン幾何を保持しつつ学習を直接行う動機付け。
- SPD 行列上で層を跨ぐ深層アーキテクチャ(SPDNet)を提案。
- SPD 変換重みのための Stiefel 多様体上での逆伝播と最適化を開発。
- 感情、アクション、顔認証タスクで浅い SPD 手法より性能が向上することを示す。
提案手法
- BiMap 層: X_k = W_k X_{k-1} W_k^T で W_k を Stiefel 多様体上に置き Outputs を SPD に保つ。
- ReEig 層: X_k に SPD 特異値の ReLU-like 非線形性を適用する。X_k = U diag(max(εI, Σ)) U^T。
- LogEig 層: 固有値に対して対数を計算し SPD をユークリッド空間へ写像して標準的な FC/softmax 層を適用。
- リーマン幾何バックプロップ: Stiefel 多様体上の SGD で retraction ステップを用いて BiMap 重みを更新。
- 行列バックプロパゲーション: ReEig および LogEig 層の固有値分解を行う際に行列連鎖規則の拡張を用いて勾配を導出。
- 訓練の詳細: 四つの設定(0–3 BiRe ブロック)、学習率 1e-2、ランダムな半直交初期化、ε = 1e-4。
実験結果
リサーチクエスチョン
- RQ1SPD マ manifolds 上で SPD 構造を保持しつつ深層非線形学習を直接行えるか。
- RQ2BiMap および ReEig 層は LogEig 変換を超える意味のある非線形性を SPD 行列に提供するか。
- RQ3SPDNet + リーマンバックプロパゲーションは標準的な視覚タスクで既存の浅い SPD 学習法と比較してどうか。
主な発見
| Method | AFEW | HDM05 | PaSC1 | PaSC2 |
|---|---|---|---|---|
| STM-ExpLet | 31.73% | – | – | – |
| RSR-SPDML | 30.12% | 48.01% ±3.38 | – | – |
| DeepO2P | 28.54% | – | 68.76% | 60.14% |
| CDL | 31.81% | 41.74% ±1.92 | 78.29% | 70.41% |
| LEML | 25.13% | 46.87% ±2.19 | 66.53% | 58.34% |
| SPDML-AIM | 26.72% | 47.25% ±2.78 | 65.47% | 59.03% |
| SPDML-Stein | 24.55% | 46.21% ±2.65 | 61.63% | 56.67% |
| RSR | 27.49% | 41.12% ±2.53 | – | – |
| SPDNet-0BiRe | 26.32% | 48.12% ±3.15 | 68.52% | 63.92% |
| SPDNet-1BiRe | 29.12% | 55.26% ±2.37 | 71.75% | 65.81% |
| SPDNet-2BiRe | 31.54% | 59.13% ±1.78 | 76.23% | 69.64% |
| SPDNet-3BiRe | 34.23% | 61.45% ±1.12 | 80.12% | 72.83% |
- SPDNet-3BiRe は AFEW で 34.23%、HDM05 で 61.45%、PaSC1 で 80.12%(PaSC2: 72.83)を達成し、いくつかの浅い SPD 手法を上回る。
- より深い SPDNet 構成(より多くの BiRe ブロック)は SPDNet-0BiRe および SPDNet-1/2BiRe より一貫した性能向上を示す。
- LogEig 層は必須であり、これを省くと精度が著しく低下する(例: SPDNet-0BiRe の 26.32% 対 SPDNet-3BiRe の 34.23% で AFEW)。
- SPDNet-3BiRe は DeepO2P および他の SPD 学習ベースラインを AFEW、HDM05、PaSC データセット全体で上回る。
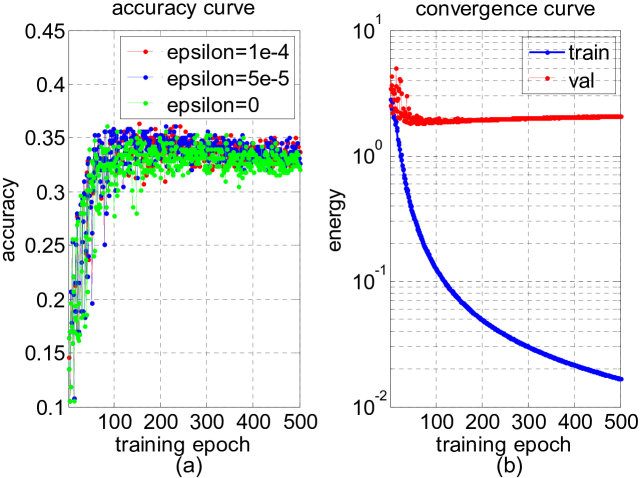
- 実験は手法が収束し、非線形固有値整合化(ε パラメータの検討)から利益を得ることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。