[論文レビュー] A Roadmap to Pluralistic Alignment
本論文はAIモデルの三つの形態の多元主義(Overton、Steerable、Distributional)を定義し、それに対応する三つのベンチマーククラス(multi-objective、trade-off steerable、jury-pluralistic)を提案し、現在の整合性が distributional pluralism を低下させる可能性があるという実証的な懸念を提示し、pluralistic evaluation と alignment の研究課題を概説する。
With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed. We identify and formalize three possible ways to define and operationalize pluralism in AI systems: 1) Overton pluralistic models that present a spectrum of reasonable responses; 2) Steerably pluralistic models that can steer to reflect certain perspectives; and 3) Distributionally pluralistic models that are well-calibrated to a given population in distribution. We also formalize and discuss three possible classes of pluralistic benchmarks: 1) Multi-objective benchmarks, 2) Trade-off steerable benchmarks, which incentivize models to steer to arbitrary trade-offs, and 3) Jury-pluralistic benchmarks which explicitly model diverse human ratings. We use this framework to argue that current alignment techniques may be fundamentally limited for pluralistic AI; indeed, we highlight empirical evidence, both from our own experiments and from other work, that standard alignment procedures might reduce distributional pluralism in models, motivating the need for further research on pluralistic alignment.
研究の動機と目的
- 多様な人間の価値観と視点に奉仕するためのAI整合における多元主義の重要性を動機づける。
- モデルにおける三つの多元主義の運用化を形式化する:Overton、Steerable、Distributional。
- 多様な目的と集団に対してモデルを評価するための三つのクラスの多元主義ベンチマークを提案する。
- 現在の整合技術が distributional pluralism を低下させる可能性を示し、今後の研究方向を概説する。
提案手法
- Overton 多元主義の形式的定義(合理的な回答全体を出力すること)と、それを運用可能にするメカニズム。
- Steerable 多元主義の形式的定義(属性や視点に応じて応答を条件付けすること)と信頼性を測る手法。
- Distributional 多元主義の形式的定義(回答に対するターゲット集団分布を一致させること)とキャリブレーションを評価する指標。
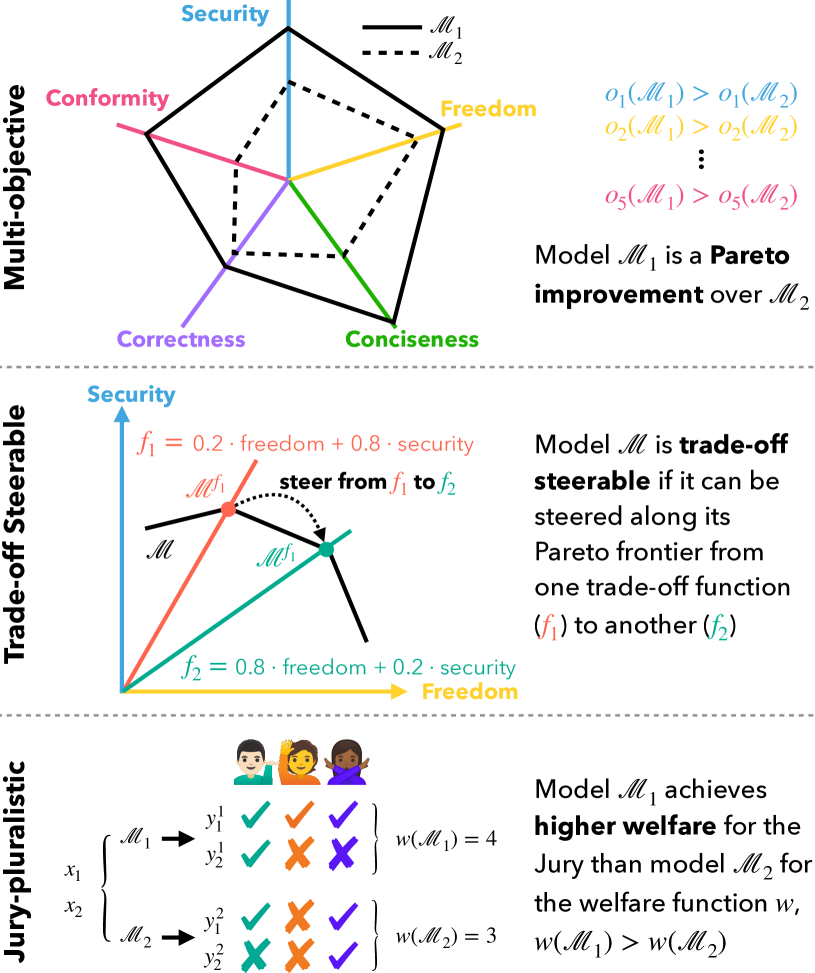
- 三つのベンチマーク族の定義:multi-objective ベンチマーク、trade-off steerable ベンチマーク、jury-pluralistic ベンチマーク。
- 整合処理と、RLHF/後整合が distributional pluralism を低下させ得るという経験的観察の議論。

実験結果
リサーチクエスチョン
- RQ1AI システムにおいて平均的な人間の嗜好を超えて、どのように多元主義を定義し運用可能にできるか?
- RQ2モデルの多元主義を測るのに適したベンチマーク設計は何か(Overton、steerable、distributional)?
- RQ3現在の整合技術(例:RLHF)は distributional pluralism を低下させるのか、どの条件下でそうなるのか?
- RQ4実用的なLLMアプリケーションにおいてOverton、steerable、distributional pluralismをどのように実装・評価するか?
- RQ5多元的な評価と整合戦略を開発するために、今後どのような研究が必要か?
主な発見
- モデルの多元主義の三つの形式化:Overton(合理的な回答の全スペクトラム)、Steerable(属性忠実な誘導)、Distributional(母集団適合分布)。
- 三つのベンチマーククラスの提案:multi-objective ベンチマーク、trade-off steerable ベンチマーク、jury-pluralistic ベンチマーク(多様な評価を明示的にモデル化するための)
- 標準的な整合が distributional pluralism を低下させる可能性を示す経験的・理論的示唆があり、多元的評価と整合アプローチのさらなる研究を促す。
- 各多元主義タイプとベンチマーククラスの実践的制限と適用についての議論。
- 多元的な評価と整合に向けたロードマップと今後の研究提言。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。