[論文レビュー] A Safe Harbor for AI Evaluation and Red Teaming
本論文は、生成系AIシステムの独立した公益目的の評価とレッドチーミングを法的責任とアカウント停止リスクから保護するための法的および技術的なセーフハーバーを提案している。
Independent evaluation and red teaming are critical for identifying the risks posed by generative AI systems. However, the terms of service and enforcement strategies used by prominent AI companies to deter model misuse have disincentives on good faith safety evaluations. This causes some researchers to fear that conducting such research or releasing their findings will result in account suspensions or legal reprisal. Although some companies offer researcher access programs, they are an inadequate substitute for independent research access, as they have limited community representation, receive inadequate funding, and lack independence from corporate incentives. We propose that major AI developers commit to providing a legal and technical safe harbor, indemnifying public interest safety research and protecting it from the threat of account suspensions or legal reprisal. These proposals emerged from our collective experience conducting safety, privacy, and trustworthiness research on generative AI systems, where norms and incentives could be better aligned with public interests, without exacerbating model misuse. We believe these commitments are a necessary step towards more inclusive and unimpeded community efforts to tackle the risks of generative AI.
研究の動機と目的
- 生成型AIシステムの独立した評価とレッドチーミングを動機づけ、リスクを特定する。
- 研究者が真摯な安全性研究を実施することを妨げる法的・政策的・実務的障壁を浮き彫りにする。
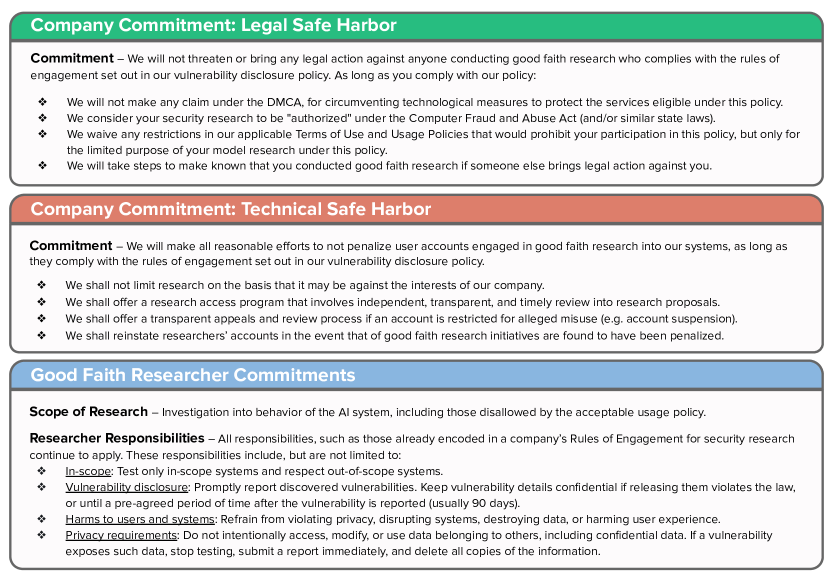
- 研究者を保護するための2つの自主的コミットメント(法的セーフハーバーと技術的セーフハーバー)を提案する。
- 脆弱性公表の規範と信頼できる第三者を活用した実装経路を概説する。
- AIの安全性と説明責任を向上させるため、より広範で独立した参加を促進する。
提案手法
- 法令遵守に適した枠組みを支えるため、主要用語(セーフハーバー、善意の研究、脆弱性公表)を定義し、文脈を示す。
- 主要なAI開発者を横断する現行の利用規約、執行慣行、研究者アクセスプログラムを分析する。
- 独立した安全性研究のための法的セーフハーバーと技術的セーフハーバーの2つの連携コミットメントを主張する。
- アクセス権付与を信頼できる第三者(例:大学、非営利団体)へ委任して、規模を拡大しアクセスの政治化を抑止する。
- 研究者を保護しつつ悪用を防ぐ、独立審査、異議申立て、および透明なプロセスの仕組みを概説する。
- 提案を既存の安全性研究およびガバナンス文献(例:バグバウンティ、NAIRR、政策ガイドライン)に位置づける。
実験結果
リサーチクエスチョン
- RQ1現行の利用規約と執行慣行は、独立したAI評価とレッドチーミングをどのように抑止しているのか。
- RQ2善意の安全性研究を行う研究者を保護するために、どのような法的および技術的保護が必要か。
- RQ3誤用を可能にせず、独立評価を拡大するために、セーフハーバーを実践的にどのように実装できるか。
- RQ4研究アクセスの認可において、大学、非営利団体、公共の利益団体はどのような役割を果たすべきか。
- RQ5独立した安全性研究を維持するために、どのようなガバナンス機構(異議申立、透明性)が必要か。
主な発見
- 独立したAI評価は、一貫性のない不透明な方針とアカウント停止の脅威によって妨げられている。
- 現在の研究者アクセスプログラムは代表性に欠け、資金不足で、企業の動機から独立性を欠いている。
- 法的セーフハーバーと技術的セーフハーバーという自主的コミットメントのペアは、参加を大幅に増やし、研究者を保護できる。
- 信頼できる第三者へのアクセス権限委任と透明な異議申立ての確立は、企業の特定への偏りと委縮効果を低減できる。
- 法的セーフハーバーは、既設の脆弱性公表方針の下で行われる善意の研究を保護し、技術的セーフハーバーは研究者をアカウント停止から保護する。
- これらの保護は、安全性研究を公的利益と alignmentさせ、モデルの悪用防止の safeguards を損なわない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。