[論文レビュー] A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
本論文はLLMの安全性と信頼性の脆弱性を検討し、検証と妥当性(V&V)技術をLLMライフサイクル全体に適用する方法を概観し、反証、検証、実行時モニタリング、倫理・規制上の考慮を含むフレームワークを提案する。
Large Language Models (LLMs) have exploded a new heatwave of AI for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities and limitations of the LLMs, categorising them into inherent issues, attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks as independent processes to check the alignment of their implementations against the specifications, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and regulations and ethical use. In total, 370+ references are considered to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V. While intensive research has been conducted to identify the safety and trustworthiness issues, rigorous yet practical methods are called for to ensure the alignment of LLMs with safety and trustworthiness requirements.
研究の動機と目的
- LLMsの安全性と信頼性の脆弱性を特定し、分類する(本質的な問題、攻撃、意図しないバグ)。
- LLMライフサイクルに検証と妥当性の技法を統合して、厳密な安全性分析を実現する方法を探る。
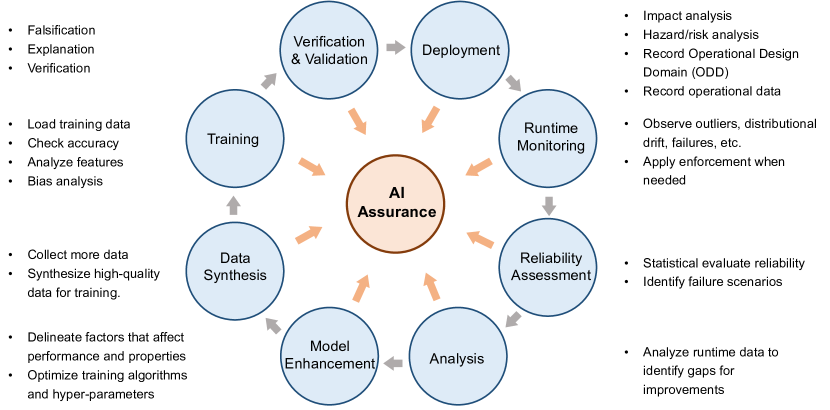
- 反証/評価、検証、実行時モニタリング、倫理/規制を含むAI保証を支援するフレームワークを提示する。
- LLMの開発と導入における主要な安全機構としてのRLHFとガードレールを論じる。
提案手法
- 既知のLLM脆弱性をレビューし、分類する(本質的な問題、攻撃、意図しないバグ)。
- LLMのライフサイクル全体におけるV&V技法(反証、検証、実行時モニタリング)の適用可能性を分析する。
- 文献を総合して(370件以上の References)V&V技法を安全性と信頼性の目標へ対応づける。
- LLMsとAI保証に合わせた補完的なV&Vフレームワークを提案する。
実験結果
リサーチクエスチョン
- RQ1LLMのライフサイクル全体を通じた主な安全性と信頼性の脆弱性は何か?
- RQ2伝統的なV&V技法を現実のLLMの検証と妥当性評価に適用・拡張するにはどうすればよいか?
- RQ3RLHFとガードレールは、LLMsを安全要件に適合させる上でどのような役割を果たすか?
- RQ4既存のベンチマーク、モニタリング戦略、規制上の考慮事項は、LLMの安全性に関してどのような指針を提供しているか?
- RQ5脆弱性の特定と実践的な検証・評価手法の間に、どのようなギャップが残っているか?
主な発見
- LLMsは安全性と信頼性に影響を与える固有の性能と持続可能性の問題を示す。
- 攻撃(プライバシー漏洩、バックドア、POISONING、偽情報)と意図しないバグが展開時に追加のリスクをもたらす。
- ブラックボックス型のV&Vと実行時モニタリングは、LLMの非決定性とスケールを考慮すると不可欠で、拡張可能で実用的な評価手法の必要性がある。
- RLHFとガードレールは現行の安全戦略の中心だが、有用性と有害性回避の間にトレードオフを生む可能性がある。
- ライフサイクル全段階の安全性と信頼性要件に整合させるため、厳密でありながら実用的なV&V手法の強い需要がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。