[論文レビュー] A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law
本調査は、金融、医療、法務における大規模言語モデル(LLMs)の適用方法を分析し、性能を評価し、課題と倫理を議論し、ドメイン固有のタスク、データセット、マルチモーダルな観点に焦点を当てた将来の方向性を概説します。
In the fast-evolving domain of artificial intelligence, large language models (LLMs) such as GPT-3 and GPT-4 are revolutionizing the landscapes of finance, healthcare, and law: domains characterized by their reliance on professional expertise, challenging data acquisition, high-stakes, and stringent regulatory compliance. This survey offers a detailed exploration of the methodologies, applications, challenges, and forward-looking opportunities of LLMs within these high-stakes sectors. We highlight the instrumental role of LLMs in enhancing diagnostic and treatment methodologies in healthcare, innovating financial analytics, and refining legal interpretation and compliance strategies. Moreover, we critically examine the ethics for LLM applications in these fields, pointing out the existing ethical concerns and the need for transparent, fair, and robust AI systems that respect regulatory norms. By presenting a thorough review of current literature and practical applications, we showcase the transformative impact of LLMs, and outline the imperative for interdisciplinary cooperation, methodological advancements, and ethical vigilance. Through this lens, we aim to spark dialogue and inspire future research dedicated to maximizing the benefits of LLMs while mitigating their risks in these precision-dependent sectors. To facilitate future research on LLMs in these critical societal domains, we also initiate a reading list that tracks the latest advancements under this topic, which will be continually updated: \url{https://github.com/czyssrs/LLM_X_papers}.
研究の動機と目的
- 専門知識、機微データ、規制遵守が重要となるハイリスク領域におけるLLMs研究の動機付け。
- 金融・医療・法務のNLPタスク、データセット、LLMsを調査し、強み、ギャップ、今後の研究方向を特定する。
- 倫理的配慮、領域特有の要件(規制、説明性、公平性)を強調し、学際的協力の必要性を提起する。
提案手法
- 既存の金融NLPタスクとデータセット(SA、IE、QA、SMP など)を整理し、データセットとベンチマークを記録する。
- 金融LLMs、事前学習と指示調整アプローチの比較、およびタスク別の評価結果を要約する。
- 医療および法務のNLPタスク、LLMs、評価方法を調査し、マルチモーダルまたは構造化データへの配慮を行う。
- これらの領域におけるLLM展開の倫理、領域特有の懸念、規制の考慮事項を論じる。
- 将来の研究を指針とするための、領域横断的な課題と機会の総合的な考察を提供する。
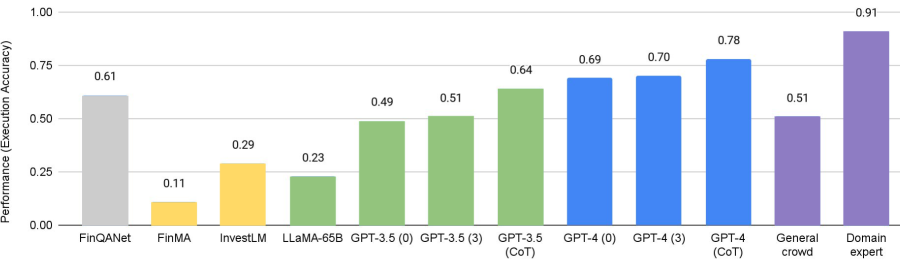
実験結果
リサーチクエスチョン
- RQ1金融、医療、法務でLLMsを評価するために用いられる主要なNLPタスクとベンチマークは何か。
- RQ2標準タスクとデータセット全般における、金融・医療・法務のLLMsの性能はどう比較されるか。
- RQ3これらの領域でLLMの能力を形づくる主要な方法論的アプローチ(事前学習、指示調整、マルチモーダル統合)は何か。
- RQ4これらの部門でLLM導入を支配する倫理的・規制・透明性の懸念は何で、どのように緩和できるか。
主な発見
| モデル | FPB | FiQA-SA | 見出し | NER FIN3 | エンティティF-1 |
|---|---|---|---|---|---|
| Fine-tuning | 0.86 | 0.84 | 0.87 | 0.95 | 0.83 |
| BloombergGPT (few-shot) | - | 0.51 | 0.75 | 0.82 | 0.61 |
| LlaMA-65B (zero-shot) | - | 0.38 | 0.75 | - | - |
| InvestLM (zero-shot) | - | 0.71 | 0.90 | - | - |
| FinMA-30B (zero-shot) | 0.87 | 0.88 | 0.87 | 0.97 | 0.62 |
| GPT-3.5 (zero-shot) | 0.78 | 0.78 | 0.76 | 0.72 | 0.29 |
| GPT-3.5 (few-shot) | 0.79 | 0.79 | 0.78 | 0.75 | 0.52 |
| GPT-4 (zero-shot) | 0.83 | 0.83 | 0.87 | 0.84 | 0.36 |
| GPT-4 (few-shot) | 0.86 | 0.86 | 0.88 | 0.86 | 0.57 |
- LLMsは、分析の強化、解釈、意思決定支援を目的に金融、医療、法務の各分野で拡大しているが、タスクとモダリティによって性能は異なる。
- 金融分野では、BloombergGPT、FinMA系、InvestLMなどの専門化LLMsが感情分析、QA、情報抽出で改善を示す一方、マルチモーダル推論や数値推論は依然として課題。
- 医療応用は、医療NLP、異常検知、医療レポート生成、画像-言語タスクなどを含み、臨床現場での指示遵守と評価への注目が高まっている。
- 法務分野のLLMsは、契約分析、法令解釈、判例QAなどのタスクで進展しており、ハイリスクな法的設定での解釈性と信頼性を重視している。
- 倫理的配慮—プライバシー、データセキュリティ、バイアス、説明性、規制遵守—は三領域すべてで中心となっており、透明で公正かつ監査可能なAIシステムを必要とする。
- 調査された文献は、小規模ドメイン微調整から、より大規模な指示調整型および多言語/マルチモーダルLLMsへの傾向を浮き彫りにしており、より良い評価基準とデータガバナンスの要請とともにある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。