[論文レビュー] A Survey on Mamba Architecture for Vision Applications
この調査は Vision Mamba(ViM)と VideoMamba を詳述し、状態空間モデルを用いた bidirectional/時空スキャンニングを通じたほぼ線形スケーラビリティを視覚タスクに適用する方法を示し、画像・動画・3D タスクでの性能を比較します。
Transformers have become foundational for visual tasks such as object detection, semantic segmentation, and video understanding, but their quadratic complexity in attention mechanisms presents scalability challenges. To address these limitations, the Mamba architecture utilizes state-space models (SSMs) for linear scalability, efficient processing, and improved contextual awareness. This paper investigates Mamba architecture for visual domain applications and its recent advancements, including Vision Mamba (ViM) and VideoMamba, which introduce bidirectional scanning, selective scanning mechanisms, and spatiotemporal processing to enhance image and video understanding. Architectural innovations like position embeddings, cross-scan modules, and hierarchical designs further optimize the Mamba framework for global and local feature extraction. These advancements position Mamba as a promising architecture in computer vision research and applications.
研究の動機と目的
- 視覚データに対する状態空間モデルの適用として Mamba アーキテクチャがどのように適応されるかを評価する。
- ViM および VideoMamba の設計選択を、空間的・時間的依存性の処理に基づいて議論する。
- 位置埋め込み、クロススキャンモジュール、階層設計など、アーキテクチャ革新とそれが性能に与える影響を評価する。
- 画像、動画、マルチタスク視覚アプリケーションにおける Mamba ベースアーキテクチャの比較的ガイドラインを提供する。
提案手法
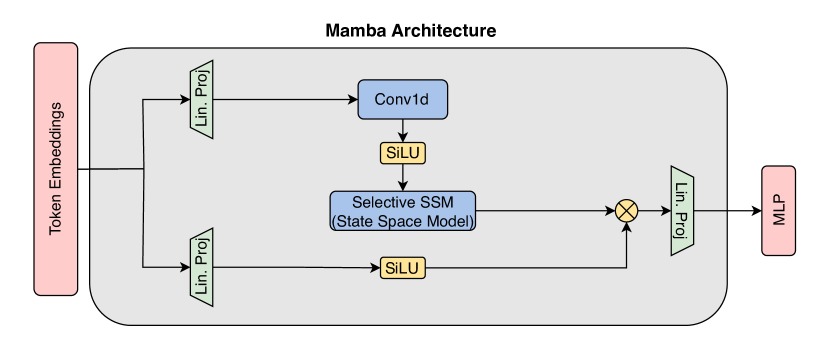
- Mamba ブロックと選択的スキャン(S6)機構を説明する。
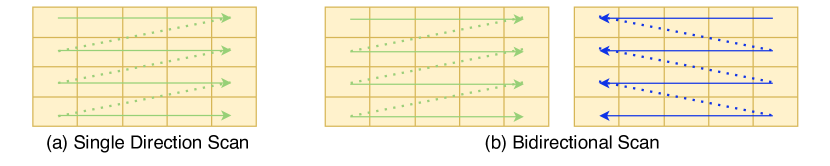
- Bidirectional スキャンと位置埋め込みを用いる Vision Mamba(ViM)を説明する。
- 3D bidirectional スキャンと時空処理を備える VideoMamba を説明する。
- Cross-Scan Module、LocalMamba、Spatial-Mamba、VSSD、Hi-Mamba、Famba-V などのアーキテクチャ変種とその目的を要約する。
- ViM と VideoMamba を標準的な視覚ベンチマークとタスクで比較する。
実験結果
リサーチクエスチョン
- RQ1ViM/VideoMamba における bidirectional および時空スキャンニングが、Transformerと比較して画像および動画タスクの性能にどのような影響を与えるか?
- RQ2どのアーキテクチャ革新(例:位置埋め込み、SASF、レジスタトークン、マスク付き逆伝播計算)は、タスク間で最も良い精度-効率のトレードオフを生み出すか?
- RQ3Imagenet-1k、ADE20K、MS-COCO、Kinetics-400、SSv2 における ViM/VideoMamba の変種の複雑さ(パラメータ数、FLOPS)と精度のトレードオフはどうか?
- RQ4視覚および動画における Transformer ベースモデルとの格差を達成するうえで、残る課題は何か?
- RQ5Mamba の適用範囲を 2D/3D 視覚およびマルチモーダル融合へ拡張する将来の方向性は何か?
主な発見
- ViM の変種は強力な画像分類性能を達成し、Vmamba-S は ImageNet-1k で Top-1 精度 83.6%、Spatial-Mamba-S は 84.6%を達成。
- Vmamba-S および Spatial-Mamba-S は ADE20K におけるセマンティックセグメンテーション性能もリードしており、Vmamba-S の約 50.6 mIoU 程度。
- MS-COCO のオブジェクト検出では Spatial Mamba-S が 54.2 AP bbox@75、VSSD-S が 53.1 AP bbox@75 を達成し、構造認識的または非因果メカニズムで高い性能を示す。
- VideoMamba の変種は長距離動画理解で優れており、VideoMamba-S が Kinetics-400 で Top-1 81.5%、VideoMambaPro-S が 88.5% を達成。
- EfficientViM-M4 は画像分類で 81.9% Top-1、パラメータ 21.3M、4.1 GFLOPS という優れた精度-効率のバランスを示す。
- VideoMambaPro-S は residual/ masked backward 戦略により VideoMamba-S を上回る精度を、同等または低い FLOPS で実現する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。