[論文レビュー] A Survey on Speech Deepfake Detection
このサーベイは、TTSおよびVCによって生成された音声ディープフェイクの音声アンスプーフィング検出を網羅し、アーキテクチャ、データセット、指標、最適化技術、およびオープンソース資源を概説し、課題と今後の方向性について議論する。
The availability of smart devices leads to an exponential increase in multimedia content. However, advancements in deep learning have also enabled the creation of highly sophisticated Deepfake content, including speech Deepfakes, which pose a serious threat by generating realistic voices and spreading misinformation. To combat this, numerous challenges have been organized to advance speech Deepfake detection techniques. In this survey, we systematically analyze more than 200 papers published up to March 2024. We provide a comprehensive review of each component in the detection pipeline, including model architectures, optimization techniques, generalizability, evaluation metrics, performance comparisons, available datasets, and open source availability. For each aspect, we assess recent progress and discuss ongoing challenges. In addition, we explore emerging topics such as partial Deepfake detection, cross-dataset evaluation, and defences against adversarial attacks, while suggesting promising research directions. This survey not only identifies the current state of the art to establish strong baselines for future experiments but also offers clear guidance for researchers aiming to enhance speech Deepfake detection systems.
研究の動機と目的
- 偽造オーディオの定義と分類を行い、完全なスプーフィングと部分的スプーフィングを含む。
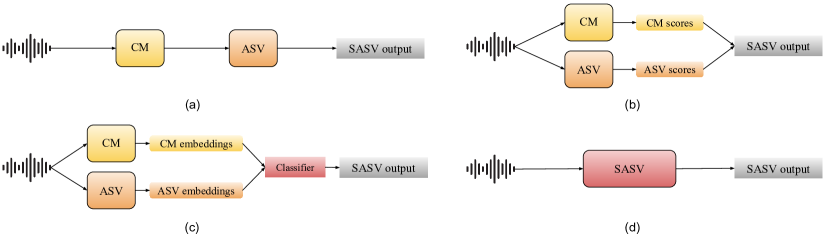
- 音声アンスプーフィング検出パイプラインとその構成要素の包括的なレビューを提供する。
- 音声スプーフィング検出のデータセット、評価指標、ベンチマークの実践を評価する。
- データ拡張、損失関数、活性化関数といったトレーニング最適化技術とそれらが性能に与える影響を分析する。
- 部分的スプーフィング、データセット間評価、敵対的防御などの新興研究トピックとオープンソースの可用性について議論する。
提案手法
- 検出アーキテクチャをフロントエンドの特徴抽出からバックエンド分類器、エンドツーエンドモデルまで系統的にレビューする。
- 特徴抽出アプローチを手作りスペクトル特徴、ディープラーニング特徴、分析指向特徴に分類する。
- 完全および部分的に偽装データと実データセットを含む、音声アンスプーフィングで使用されるデータセットと指標を評価する。
- データ拡張、損失関数、活性化選択がモデル性能に与える影響を含むトレーニング最適化技術の評価。
- 再現性のある研究を可能にするオープンソース資源とベンチマークの実践について議論する。
- 分野の課題と今後の方向性を特定する。

実験結果
リサーチクエスチョン
- RQ1完全に偽装された音声(TTS/VC)および部分的に偽装されたセグメントで堅牢な検出を生み出すアーキテクチャと特徴は何か?
- RQ2データセット、未知の攻撃、コーデックがベンチマーク全体の一般化と評価指標にどう影響するか?
- RQ3トレーニング技術(拡張、損失関数、活性化の選択)が検出性能に与える影響は?
- RQ4新興トピック(部分的スプーフィング、データセット横断転移、敵対的防御)と今後の研究を導くオープンソースの可用性は?
主な発見
- 本調査は、音声のアンチスプーフィングに関する検出コンポーネント、データセット、指標、およびオープンソース資源の広範なスペクトルをカバーしている。
- データ拡張、活性化関数、損失関数を含むモデル学習の最適化技術を評価し、それらが性能に与える影響を論じる。
- 完全および部分的偽装シナリオ、データセット間評価、敵対的防御を新興研究トピックとして強調する。
- SOTAモデルとベンチマークデータセットに関するオープンソース情報を提供し、再現性のある研究を促進する。
- SOTAの性能、一般化、データセットの多様性における現在の課題を特定し、今後の研究の方向性を提案する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。