QUICK REVIEW
[論文レビュー] A Survey on Transformers in Reinforcement Learning
Wenzhe Li, Hao Luo|arXiv (Cornell University)|Jan 8, 2023
Reinforcement Learning in Robotics被引用数 16
ひとこと要約
Transformerアーキテクチャが強化学習にどのように用いられているかの包括的な調査。表現、世界モデル、逐次意思決定、および汎用エージェントを含む、分類と今後の方向性。
ABSTRACT
Transformer has been considered the dominating neural architecture in NLP and CV, mostly under supervised settings. Recently, a similar surge of using Transformers has appeared in the domain of reinforcement learning (RL), but it is faced with unique design choices and challenges brought by the nature of RL. However, the evolution of Transformers in RL has not yet been well unraveled. In this paper, we seek to systematically review motivations and progress on using Transformers in RL, provide a taxonomy on existing works, discuss each sub-field, and summarize future prospects.
研究の動機と目的
- RLにおけるTransformerアーキテクチャの研究動機付けと、監督付き学習と比較しての独自の課題を特定する。
- TransformerベースのRL手法の分類学を提供し、サブ分野全体の代表的な研究を要約する。
- RLにおける状態表現、世界モデル、および直接的な逐次意思決定においてTransformerがどのように用いられるかを分析する。
- 非定常性、サンプル効率、計算要件などの実務的課題を議論し、今後の方向性を整理する。
提案手法
- RLにおけるTransformersに関する既存文献を調査し、構造化された分類学(表現学習、モデル学習、逐次意思決定、汎用エージェント)に整理する。
- Transformersが局所的な各 timestep および時系列シーケンスのエンコーダとしてどのように用いられるかを、多エンティティ観測やメモリベースのポリシーを含めて説明する。
- 履歴に条件付けされ、モデルベースRLでの計画を可能にするTransformerベースの世界モデルを説明する。
- RLを条件付きシーケンスモデリングとして扱うオフラインRLの定式化を要約する(Decision Transformerおよび派生形)。
- アーキテクチャの改善と条件付け戦略(return-to-go、後知恵情報)およびロバスト性戦略(世界モデルとポリシーを分離する等)を強調する。
- 課題(非定常性、データ効率、計算/メモリコスト)を議論し、今後の方向性を提案する。
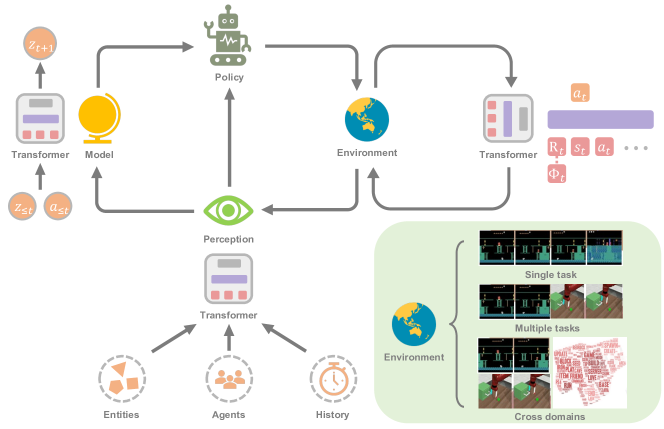
実験結果
リサーチクエスチョン
- RQ1強化学習にTransformerアーキテクチャを適用する動機と利点は何か?
- RQ2RLにおけるTransformerベースの手法はどのように分類されるか(表現、モデル学習、逐次意思決定、汎用エージェント)と、各カテゴリーの代表的なアプローチは何か?
- RQ3どのような条件付けシグナルとアーキテクチャの変更がTransformerベースのRLの性能と頑健性を向上させるか?
- RQ4RLにおけるTransformerの使用を妨げる主な課題は何か、オフラインRLや関連パラダイムはそれらにどう対処しているか?
- RQ5TransformersをRLの基盤モデルとして確立するための将来の方向性は何か?
主な発見
- TransformersはRLにおいて表現学習者としても、完全な逐次意思決定者としても適用されており、メモリ、関係推論、長期的タスクで顕著な成功を収めている。
- 履歴に条件付けされた世界モデルは、モデルベースRLにおけるデータ効率と長期予測を改善できる。
- Decision Transformerおよび関連研究はRLを条件付きシーケンスモデリングとして再構成し、オフラインデータフレームワーク内での計画と模倣を可能にした。
- さまざまな条件付けシグナル(return-to-go、後知恵情報、タスク固有の手がかり)とアーキテクチャ変種(内側/外側のTransformers、別々の世界モデルとポリシーモデル)は、異なるRL設定において頑健性と性能を向上させる。
- Transformersを活用したオフラインRLおよびオフラインからオンラインへの戦略は、RLに固有の非定常性とサンプル効率の課題に対処する。
- 改善にもかかわらず、RLにおけるTransformersは高い計算/メモリコストとデータ要求に直面しており、効率性に焦点を当てた研究やオフライン寄りのアプローチを促している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。