[論文レビュー] A Touch, Vision, and Language Dataset for Multimodal Alignment
この論文は TVL データセットを紹介する(44K の vision-tactile ペア、 人間と GPT-4V ラベルを含む)と、視覚・言語に整合した触覚エンコーダを訓練し、触覚-視覚-言語モデル(TVLM)を実現して、視覚と触覚入力から触覚記述を生成し、多模態の整合を改善する。
Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
研究の動機と目的
- オープンボキャVocabularyタスクのためのマルチモーダル言語モデルに触覚 sensing を統合する動機づけ。
- 人間と GPT-4V の注釈を含む大規模な野外データセットを作成する。
- 視覚-言語に整合した触覚エンコーダと触覚-視覚-言語モデル(TVLM)を訓練する。
- ベースラインと比較して触覚-視覚-言語の整合と生成を改善することを示す。
- GPT-4V を用いた疑似ラベル付けが限られた人間ラベルと組み合わせることで補完可能であることを示す。
提案手法
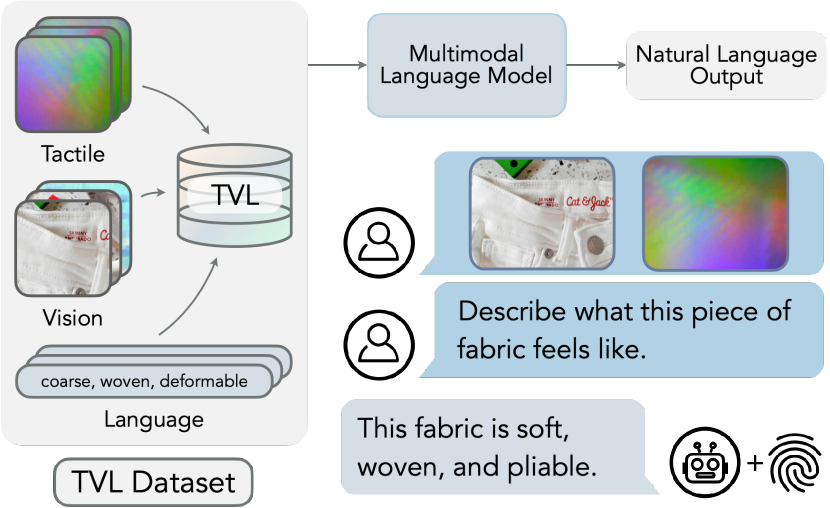
- ハンドヘルド機器を用いた野外データを含む 44K の vision-tactile データセット(TVL)を収集し、視覚と触覚のリーディングを同期させる。
- データの 10% を人間の触覚言語記述で注釈し、残りの 90% は GPT-4V を用いて疑似ラベル付けする。
- 触覚-言語、触覚-視覚、視覚-言語の対を横断する対比学習を用いて、OpenCLIP 埋め込みに整合した触覚エンコーダを訓練する。
- 視覚と触覚入力を組み合わせて触覚記述を生成する言語能力を持つモデル(TVL-LLaMA)を微調整する。
- TVL ベンチマークを用いて、クロスモーダル分類タスクと触覚意味生成タスクを評価し、真のアノテーションと照合してスコアを算出する。
実験結果
リサーチクエスチョン
- RQ1オープンボキャVocabulary設定で触覚データを視覚と言語にどのように整合させることができるか。
- RQ2人間ラベルと GPT-4V ラベルの混合監督が、触覚-視覚-言語の整合と生成を改善するか。
- RQ3視覚およびテキストモダリティに整合した触覚エンコーダはオープンボキャVocabularyの触覚記述生成を支援できるか。
- RQ4TVLM は触覚-視覚-言語のベンチマークで既存の視覚言語モデルや GPT-4V と比べてどうか。
主な発見
- TVL エンコーダは触覚-言語の整合を改善し、任意の単一モダリティのペアリングで訓練されたモデルより分類精度が +29% 高いことを示す。
- TVL-LLaMA モデルは TVL ベンチマークで GPT-4V およびオープンソースの視覚言語モデルを上回り、少なくとも +12% および +32% の改善を示す。
- 人間ラベルと疑似ラベルの両方を使用することで、1つのラベルソースのみを使用する場合よりも多模態理解が向上する。
- TVL ベンチマーク上のオープンボキャ Vocabulary 触覚分類は、TVL データセットで訓練された触覚エンコーダとともに実現可能である。
- GPT-4V の疑似ラベルは、少量の人間注釈と組み合わせるとデータの有用性を効果的に拡張する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。