[論文レビュー] A Vision-Language Foundation Model to Enhance Efficiency of Chest X-ray Interpretation
本論文は胸部X線解釈のためのビジョン-言語基盤モデルを構築・評価するために CheXinstruct、CheXagent、CheXbench を導入し、ベースラインに対して顕著な改善を達成し、公平性を評価する。
Over 1.4 billion chest X-rays (CXRs) are performed annually due to their cost-effectiveness as an initial diagnostic test. This scale of radiological studies provides a significant opportunity to streamline CXR interpretation and documentation. While foundation models are a promising solution, the lack of publicly available large-scale datasets and benchmarks inhibits their iterative development and real-world evaluation. To overcome these challenges, we constructed a large-scale dataset (CheXinstruct), which we utilized to train a vision-language foundation model (CheXagent). We systematically demonstrated competitive performance across eight distinct task types on our novel evaluation benchmark (CheXbench). Beyond technical validation, we assessed the real-world utility of CheXagent in directly drafting radiology reports. Our clinical assessment with eight radiologists revealed a 36% time saving for residents using CheXagent-drafted reports, while attending radiologists showed no significant time difference editing resident-drafted or CheXagent-drafted reports. The CheXagent-drafted reports improved the writing efficiency of both radiology residents and attending radiologists in 81% and 61% of cases, respectively, without loss of quality. Overall, we demonstrate that CheXagent can effectively perform a variety of CXR interpretation tasks and holds potential to assist radiologists in routine clinical workflows.
研究の動機と目的
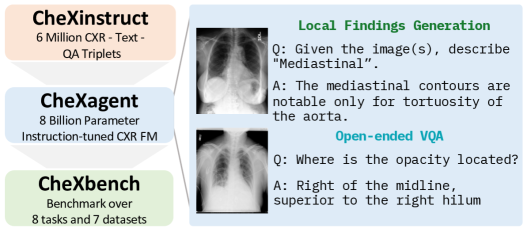
- 胸部X線の複数タスクに跨る大規模命令チューニングデータセット(CheXinstruct)を作成する。
- 胸部X線解釈用の8Bパラメータのビジョン-ラングエージ基盤モデル(CheXagent)を開発する。
- 臨床LLM、CXR視覚エンコーダ、ブリッジングモジュールを含む学習パイプラインで、視覚と言語を橋渡しする。
- CXRsにおける画像認識とテキスト理解の両領域でFMの性能を評価する CheXbench を確立する。
- 透明性を高めるため、性別、人種、年齢にわたるモデルの公正性を評価する。
提案手法
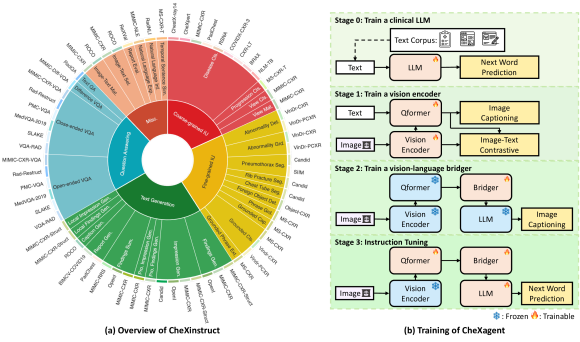
- CXRsのために CheXinstruct を 34 タスクと 65 データセットから組み立て、6.1M 件の指示-回答のトリプレットを作成する。
- 視覚エンコーダ、視覚言語ブリジャー、言語デコーダを備えた CheXagent を構築し、臨床テキストへの適応を含む4段階で訓練する。
- Stage 0: PMC abstracts、MIMIC-IV radiology reports、discharge summaries、Wikipedia terms、CheXinstruct data を用いて臨床LLMを訓練する。
- Stage 1: MIMIC-CXR、PadChest、BIMCV-COVID-19 データセット上で ITC および IC 目的を用いて CXR 視覚エンコーダを訓練する。
- Stage 2: LLMと視覚エンコーダを凍結したまま、画像とテキスト表現を整合させるために vision-language bridger を訓練する。
- Stage 3: CheXinstruct タスクで、回答に焦点を当てた次単語予測目的で多模態モデルを命令チューニングする。
実験結果
リサーチクエスチョン
- RQ1大規模な命令チューニングデータセットは、多模態基盤モデルによる堅牢なCXR解釈を可能にするか。
- RQ2CXRsで事前学習した視覚言語FMは、一般領域および医療領域のFMと比較して、主要な認識タスクとテキスト生成タスクの性能をどう発揮するか。
- RQ3このようなモデルの性別、人種、年齢に関する公平性の意味と潜在的な偏りは何か。
- RQ4提案された CheXbench は、マルチモーダルなCXR解釈タスクの信頼できるベンチマークフレームワークを提供するか。
- RQ5所見生成と要約タスクで、放射線科医レベルの品質をどの程度達成できるか。
主な発見
- CheXagent は CheXbench axis 1 全体で一般領域FMを平均 97.5% 上回る。
- CheXagent は axis 1 全体で医療領域FMを平均 55.7% 上回る。
- View分類では、MIMIC-CXRとCheXpertデータセットでベースラインに対して大きな性能向上(ほぼ完璧に近い)を示す。
- 視覚質問応答では、CheXagent は強い結果を出し、ホールドアウトデータセット(SLAKE、Rad-Restruct)へ一般化する。
- テキスト生成タスクでは、CheXagent は private および MIMIC-CXR データセットで所見生成が優れ、要約性能はより大きなLLMと比較して競争力がある。
- 放射線科医のリーダー研究では、CheXagent は所見の要約で医師と同程度とされ、所見生成のギャップを指摘し、改善のための定性的洞察を提供する。
- 公正性分析は性別、人種、年齢にわたる性能の差を明らかにし、多様なデータとバイアス緩和の必要性を強調する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。