[論文レビュー] Accelerating Large Language Model Decoding with Speculative Sampling
スペキュレイティブ・サンプリングは、高速ドラフトモデルで複数のトークンを下書きし、改良されたリジェクションサンプリング式を用いてターゲットモデルの分布を保つことで、ターゲットモデルを変更せずにChinchilla 70Bで2–2.5×のデコーディング速度向上を実現します。
We present speculative sampling, an algorithm for accelerating transformer decoding by enabling the generation of multiple tokens from each transformer call. Our algorithm relies on the observation that the latency of parallel scoring of short continuations, generated by a faster but less powerful draft model, is comparable to that of sampling a single token from the larger target model. This is combined with a novel modified rejection sampling scheme which preserves the distribution of the target model within hardware numerics. We benchmark speculative sampling with Chinchilla, a 70 billion parameter language model, achieving a 2-2.5x decoding speedup in a distributed setup, without compromising the sample quality or making modifications to the model itself.
研究の動機と目的
- 非常に大規模なトランスフォーマーの自己回帰デコーディングの待機時間の低減を動機付ける。
- ターゲットモデル呼び出しごとに複数の下書きトークンを生成するスペキュレイティブ・サンプリング(SpS)を提案する。
- SpSがハードウェアの数値内でターゲット分布を保つことを示し、ターゲットモデルを変更せずに展開できることを示す。
- 自然言語タスク全般でChinchillaサイズのモデルで実質的なスピードアップを示しつつ、サンプル品質を維持する。
提案手法
- 高速ドラフトモデル(オートレグレシブまたはパラレル)を用いて長さKの短いドラフトを生成する。
- より大きなターゲットモデルでドラフトの継続をスコアリングしてログイット分布を取得する。
- ドラフトトークンを受け入れてターゲット分布を回復する改良版のリジェクション・サンプリングを適用する。
- このスキームがターゲット分布を保つことを証明する(Theorem 1)。
- 4Bドラフトモデルと70Bターゲットモデル(Chinchilla)で待機時間と品質を測定する。
- 一般的なデコード法(nucleus、top-k、temperature)との互換性を示し、他の効率化技術と組み合わせる可能性を示す。
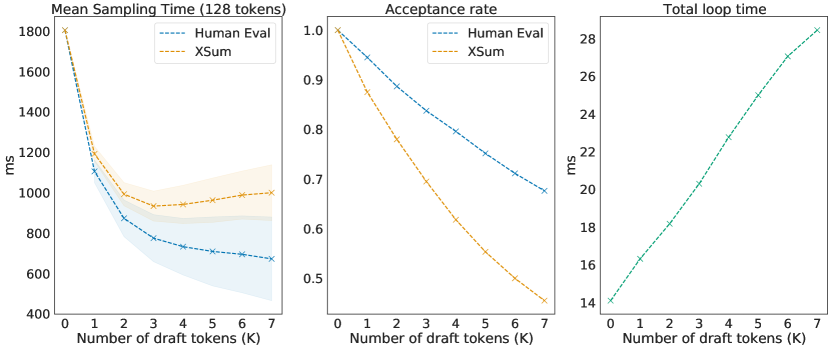
実験結果
リサーチクエスチョン
- RQ1スペキュレイティブ・サンプリングはターゲットモデルを変更せずに待機時間を削減できるか?
- RQ2ドラフト長さKと全体のスピードアップのトレードオフは、タスクとデコード戦略全体でどのようになるか?
- RQ3ドラフトトークンの受理率はドメインとデコード設定に依存し、サンプル品質は保たれるか?
主な発見
| Sampling Method | Benchmark | Result | Mean Token Time | Speed Up |
|---|---|---|---|---|
| ArS (Nucleus) | XSum (ROUGE-2) | 0.112 | 14.1ms/Token | 1× |
| SpS (Nucleus) | XSum (ROUGE-2) | 0.114 | 7.52ms/Token | 1.92× |
| ArS (Greedy) | XSum (ROUGE-2) | 0.157 | 14.1ms/Token | 1× |
| SpS (Greedy) | XSum (ROUGE-2) | 0.156 | 7.00ms/Token | 2.01× |
| ArS (Nucleus) | HumanEval (100 Shot) | 45.1% | 14.1ms/Token | 1× |
| SpS (Nucleus) | HumanEval (100 Shot) | 47.0% | 5.73ms/Token | 2.46× |
- 分散設定でChinchilla 70Bからのデコーディング速度を2–2.5×向上させることに成功。
- スペキュレイティブ・サンプリングは数値の範囲内でターゲット分布を維持し、XSumおよびHumanEvalタスクで基準と一致する経験的結果を得た。
- 4Bドラフトモデルは同じハードウェア上で1.8 ms/tokenに達し、ターゲットモデルは14.1 ms/tokenで、実用的な大幅な速度アップを可能にする。
- いくつかのケースでは自己回帰サンプリングのハードウェアのメモリ帯域幅限界を超えるスピードアップが得られる(例:HumanEvalのgreedy XSum)。
- 受理率と効率はKとドメインに依存し、最適なKはタスクごとに異なる(例:XSumの場合はK=3)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。