[論文レビュー] Accelerating LLM Inference with Staged Speculative Decoding
この論文は、ツリー構造化された推測バッチと二段階のドラフトモデルを組み合わせた段階的な推測デコードを導入し、出力品質を維持しつつ小規模バッチの端末上でのLLM推論を加速する。GPT-2-Lで最大3.16倍の高速化を達成。
Recent advances with large language models (LLM) illustrate their diverse capabilities. We propose a novel algorithm, staged speculative decoding, to accelerate LLM inference in small-batch, on-device scenarios. We address the low arithmetic intensity of small-batch inference by improving upon previous work in speculative decoding. First, we restructure the speculative batch as a tree, which reduces generation costs and increases the expected tokens per batch. Second, we add a second stage of speculative decoding. Taken together, we reduce single-batch decoding latency by 3.16x with a 762M parameter GPT-2-L model while perfectly preserving output quality.
研究の動機と目的
- デバイス上の小規模バッチ推論の算術強度の低さに対処する。
- 推測デコードを拡張して、モデル分布忠実度を損なうことなくスループットを向上させる。
- レイテンシに敏感でプライバシー保護が求められる実世界の端末上LLM性能を改善する。
提案手法
- 推測バッチを木構造化して予想トークン数を増やし並列性を有効にする。
- ドラフト2モデルを追加してデコードを加速する第二段の推測を導入する。
- オラクル、ドラフト、ドラフト2の各モデルを木構造化バッチでサンプリング・デコードし、リーフ数を最大化してKVキャッシュを再利用する。
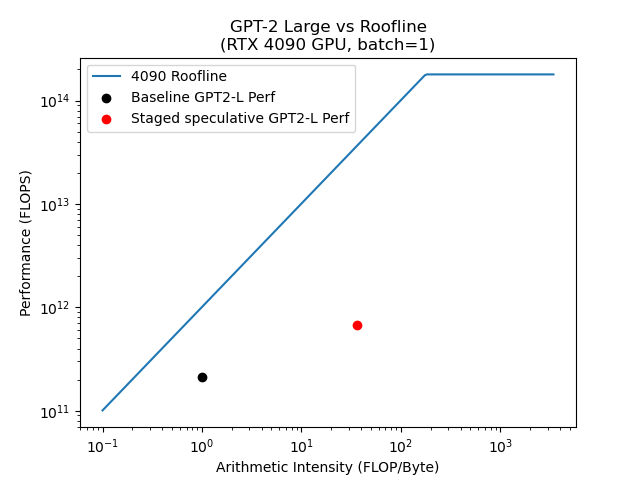
実験結果
リサーチクエスチョン
- RQ1木構造化推測バッチは小規模バッチ推論でトークンあたりのバッチを増やし帯域幅を削減できるか。
- RQ2第二段ドラフトモデルを追加して出力分布を変えずにデコードをさらに加速できるか。
- RQ3ステージド推測デコードをベースラインおよび標準的な推測デコードと比較した場合、端末ハードウェアでの速度アップと帯域削減はどの程度観測されるか。
主な発見
| Sampling | Baseline | Speculative | Staged spec. |
|---|---|---|---|
| Deterministic | 1.00 | 0.31 | 0.23 |
| Topk | 1.00 | 0.48 | 0.35 |
- ステージド推測デコードは、GPT-2-L(762M)をRTX 4090上で決定論的デコードに対してベースライン単一バッチ推論より平均3.16xの高速化を達成。
- ステージド推測デコードは、ベースラインおよび標準的推測デコードと比較してメモリ帯域を削減(決定論的: 0.23x vs 1.00ベースライン; 0.31x ベースライン vs 0.23x ステージド;Topk: 0.35x ステージド vs 0.48x 推測)。
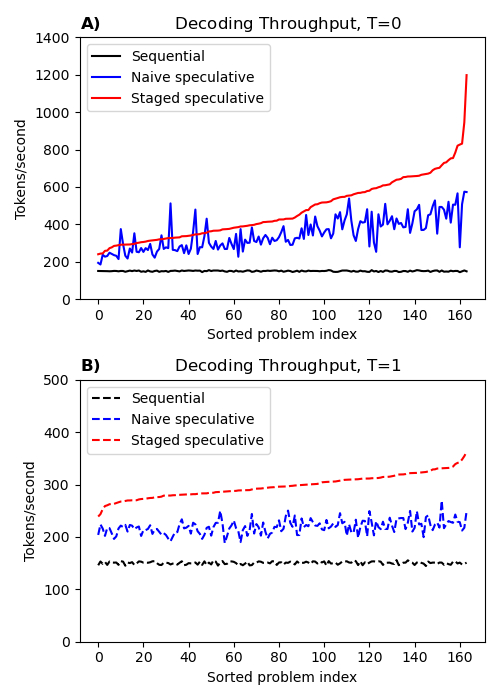
- トップ-Kサンプリング(k=50, T=1)を用いた場合、ステージド推測はベースラインより平均1.98x、標準推測デコードより1.36xの速度向上を提供。
- 内容のエントロピーに応じて難易度が異なるHumanEvalプロンプトで、スループットの向上が示され、利得が内容のエントロピーに依存することが強調される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。