[論文レビュー] Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
MCT Self-Refine (MCTSr) を導入する、LLM+MCTS フレームワークで、数学的解法を反復的に自己改良・評価し、ロールアウトを増やすことで、いくつかのオリンピック風ベンチマークでGPT-4レベルの性能を達成。
This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr's efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
研究の動機と目的
- LLMDriver の数学的推論の正確性と信頼性を高めること、特に戦略的で多段階の問題に対して。
- モンテカルロ木探索と自己改良および自己評価を組み合わせた LLM の統一フレームワークを提案すること。
- GSM8K、GSM Hard、MATH、 Olympiad レベルのデータセットを含む標準的な数学ベンチマークでの有効性を示すこと。
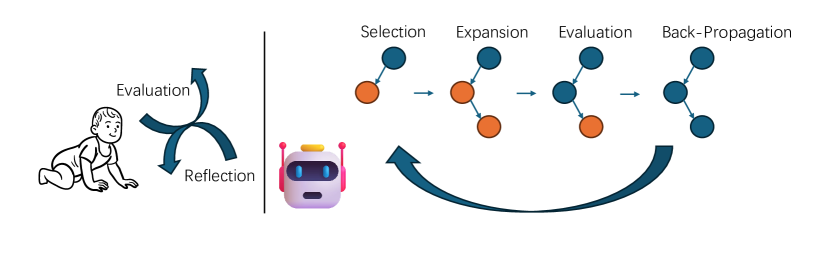
提案手法
- 新規の自己改良ループを備えたモンテカルロ木探索(MCTS)を構築し、ノードは異なる解案バージョンを表す。
- LLM駆動の改良内で探索と活用のバランスをとる、UCT に基づく改良選択を使用する。
- 各解答のQ値を自己報酬サンプルの集約から定義し、木を反復伝搬して改善を図る。
- 完全展開を決定し探索をガイドするための強化UCB式を用いた動的剪定戦略を採用する。
- 自己改良:反省的なフィードバックを生成し、マルチターンのプロンプトを介して改善された解答を作成する。
- 自己評価:プロンプトの制約、満点抑制、反復サンプリングを含む制約付きで報酬をサンプルし、Q(a) を最小値と平均報酬の半和として計算する。
実験結果
リサーチクエスチョン
- RQ1MCTS guided self-refinement は LLM が生成する数学的解法の正確性と信頼性を向上させるのか。
- RQ2ロールアウト(4 vs 8)は難易度やデータセットごとに成功率にどのような影響を与えるのか。
- RQ3小型オープンモデル(LLaMA-3 8B)はオリンピアード風問題でどの程度 GPT-4 レベルの性能に近づけるのか。
- RQ4非常に難しいオリンピアードベンチマークに対して MCTSr の実践的な限界はどこにあるのか。
主な発見
| Dataset | Zero-Shot | One-turn | 4-rollouts | 8-rollouts | Example_Nums | Note |
|---|---|---|---|---|---|---|
| GSM8K | 977 | 1147 | 1227 | 1275 | 1319 | 74.07% / 86.96% / 93.03% / 96.66% |
| GSM-Hard | 336 | 440 | 526 | 600 | 1319 | 25.47% / 33.36% / 39.88% / 45.49% |
- MCTSr はロールアウトを増やすにつれて GSM8K および GSM Hard の成功率を改善し、より簡単な GSM8K でより大きな改善を示す。
- MATH では、8 ロールアウト時に全体で 58.24% を達成(5 レベルで、ゼロショット CoT の 24.36% と比較)である。
- オリンピアードベンチマークはロールアウトを増やすと顕著な改善を示す:AIME は 2.36% から 11.79%へ、Math Odyssey は 17.22% から 49.36%へ、OlympiadBench は 1.25% から 7.76%へ。
- 比較対象のいくつかのクローズソースSOTAモデルと比べて、MCTSr 有効化済みの LLaMA-3-8B はテストデータセットで GPT-4 レベルの性能に近づく。
- この研究は、MCTS フレームワーク内で反復的な自己改良を通じてオープンモデルの数学的推論を高めるスケーラブルな道を確認した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。