[論文レビュー] AccidentGPT: Accident Analysis and Prevention from V2X Environmental Perception with Multi-modal Large Model
AccidentGPT は、V2X環境認識をGPTベースの推論と融合させ、事故を分析し、自動運転・人間運転・取締りの文脈での予防を支援する多モーダル大規模モデルを導入する。
Traffic accidents, being a significant contributor to both human casualties and property damage, have long been a focal point of research for many scholars in the field of traffic safety. However, previous studies, whether focusing on static environmental assessments or dynamic driving analyses, as well as pre-accident predictions or post-accident rule analyses, have typically been conducted in isolation. There has been a lack of an effective framework for developing a comprehensive understanding and application of traffic safety. To address this gap, this paper introduces AccidentGPT, a comprehensive accident analysis and prevention multi-modal large model. AccidentGPT establishes a multi-modal information interaction framework grounded in multi-sensor perception, thereby enabling a holistic approach to accident analysis and prevention in the field of traffic safety. Specifically, our capabilities can be categorized as follows: for autonomous driving vehicles, we provide comprehensive environmental perception and understanding to control the vehicle and avoid collisions. For human-driven vehicles, we offer proactive long-range safety warnings and blind-spot alerts while also providing safety driving recommendations and behavioral norms through human-machine dialogue and interaction. Additionally, for traffic police and management agencies, our framework supports intelligent and real-time analysis of traffic safety, encompassing pedestrian, vehicles, roads, and the environment through collaborative perception from multiple vehicles and road testing devices. The system is also capable of providing a thorough analysis of accident causes and liability after vehicle collisions. Our framework stands as the first large model to integrate comprehensive scene understanding into traffic safety studies. Project page: https://accidentgpt.github.io
研究の動機と目的
- 統合された認識と推論を用いて、静的環境、動的状態、および前後の事故タスクを横断的に分析する、包括的な交通安全分析を動機づける。
- マルチセンサV2X認識を大規模言語モデルと統合し、エンドツーエンドの事故分析と予防のための統一フレームワークを開発する。
- 自動運転車が衝突回避のために認識・予測を行える一方で、人間運転車には積極的な警告と安全ガイダンスを提供する。
- 交通警察・管理をリアルタイムでの協調認識と包括的な事故因果分析で支援する。
- 交通安全研究のための包括的なシーン理解を提供する初の大規模モデル統合を実証する。
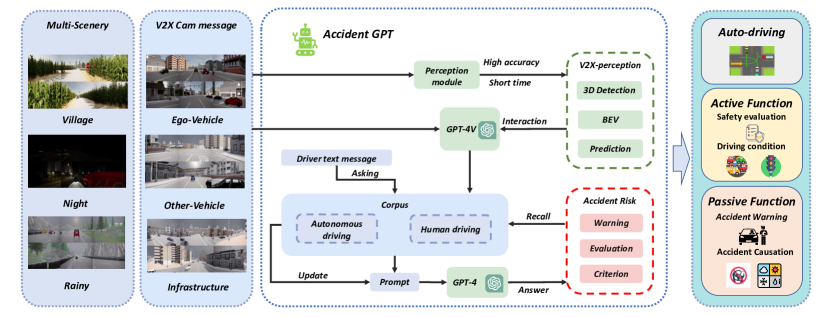
提案手法
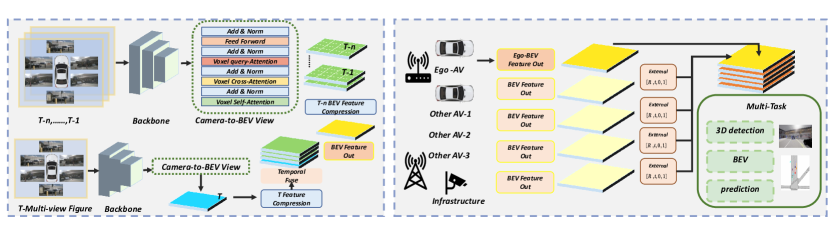
- 複数車両と路側機器のパノラマ画像を融合して3D検出、BEVマップ、軌跡予測を生成するV2X認識モジュールを作成する。
- GPT-4Vベースのマルチレベル優先サンプリングプロンプト体系、能動/受動タスクプロンプト、事故関連タスクのための専門的出力モジュールを備えたGPT推論モジュールを実装する。
- BEV特徴融合とマルチタスク検出ヘッドのためにEgoモーションで多タイムシーケンス認識データを整列させる。
- 日英? — コーパスを基盤としたプロンプティングパイプラインを開発し、時系列コーパスを動的に構築し、歴史的・文脈データを取得し、積極的・受動的なドライバープロンプトを支援する。
- LLM計算内で思考過程スタイルの推論フローを組み込み、安全な意思決定と不確実性処理を改善する。
- 運転結果から自動的にコーパスを更新し、推論とリスク評価を徐々に改善する。
実験結果
リサーチクエスチョン
- RQ1マルチ車丼? → 正しくは以下の3つの質問。
- RQ2マルチ車両および車両-道路連携認識をLLMベースの推論と統合することが、事故分析と予防にどのような影響をもたらすか?
- RQ3V2X-perception出力(3D検出、BEV認識、軌跡)をGPT-4V推論に効果的に活用して、積極的な警告と事故後の因果分析を行うにはどうすればよいか?
- RQ4能動/受動プロンプティングと反復的コーパス更新は、実世界の交通シナリオにおける安全推奨と責任評価を改善できるか?
主な発見
| Model | Detection (%) | mIOU (%) | VPQ (%) |
|---|---|---|---|
| Average Fusion [12] | 36.2 | 52.1 | 39.5 |
| DiscoNet [40] | 38.5 | 54.2 | 42 |
| V2X-ViT [41] | 40.1 | 55.1 | 43.2 |
| CoBEVT [32] | 40.8 | 56.2 | 44 |
| V2X-perception (our) | 41.07 | 57.3 | 45.2 |
- V2X-perception (our) は Table 1 に示されたベースラインより高い指標を達成し、Detection 41.07%、mIOU 57.3%、VPQ 45.2% を記録した。
- compared to other models, our approach shows improved BEV perception and trajectory prediction performance across multiple baselines.
- Table 2 indicates the model’s Car/Truck/Van/Pedestrian mATE, mASE, and mAOE metrics with the Pedestrian row providing detailed error measures (mATE 1.0017, mASE 0.9993, mAOE 1.0253).
- GPT-reasoning module enables proactive long-range safety warnings, blind-spot alerts, and driver-specific safety recommendations via human-machine dialogue.
- The framework supports real-time accident causation analysis and liability assessment for traffic management agencies.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。