[論文レビュー] Active flow control for three-dimensional cylinders through deep reinforcement learning
論文は、3D円柱表面の複数のゼロ質量流束合成ジェットを複数に対して深層強化学習(MARL)で制御し、CFDソルバーとPPOを結合させることで、ドラッグを抑制することに成功したことを示しています。
This paper presents for the first time successful results of active flow control with multiple independently controlled zero-net-mass-flux synthetic jets. The jets are placed on a three-dimensional cylinder along its span with the aim of reducing the drag coefficient. The method is based on a deep-reinforcement-learning framework that couples a computational-fluid-dynamics solver with an agent using the proximal-policy-optimization algorithm. We implement a multi-agent reinforcement-learning framework which offers numerous advantages: it exploits local invariants, makes the control adaptable to different geometries, facilitates transfer learning and cross-application of agents and results in significant training speedup. In this contribution we report significant drag reduction after applying the DRL-based control in three different configurations of the problem.
研究の動機と目的
- DRLベースの能動的流れ制御を2Dから3D円柱へ、表面アクチュエータ複数へ拡張する。
- 局所的なマルチエージェント観測を活用して高次元ジェット制御を訓練コストを過度にかけずに管理する。
- さまざまなレイノルズ数と幾何構成にわたるドラッグ低減性能を評価する。
- 3Dの尾部渦制御のMARLベンチマークを提供し、アクチュエータ配置と観測選択への洞察を得る。
提案手法
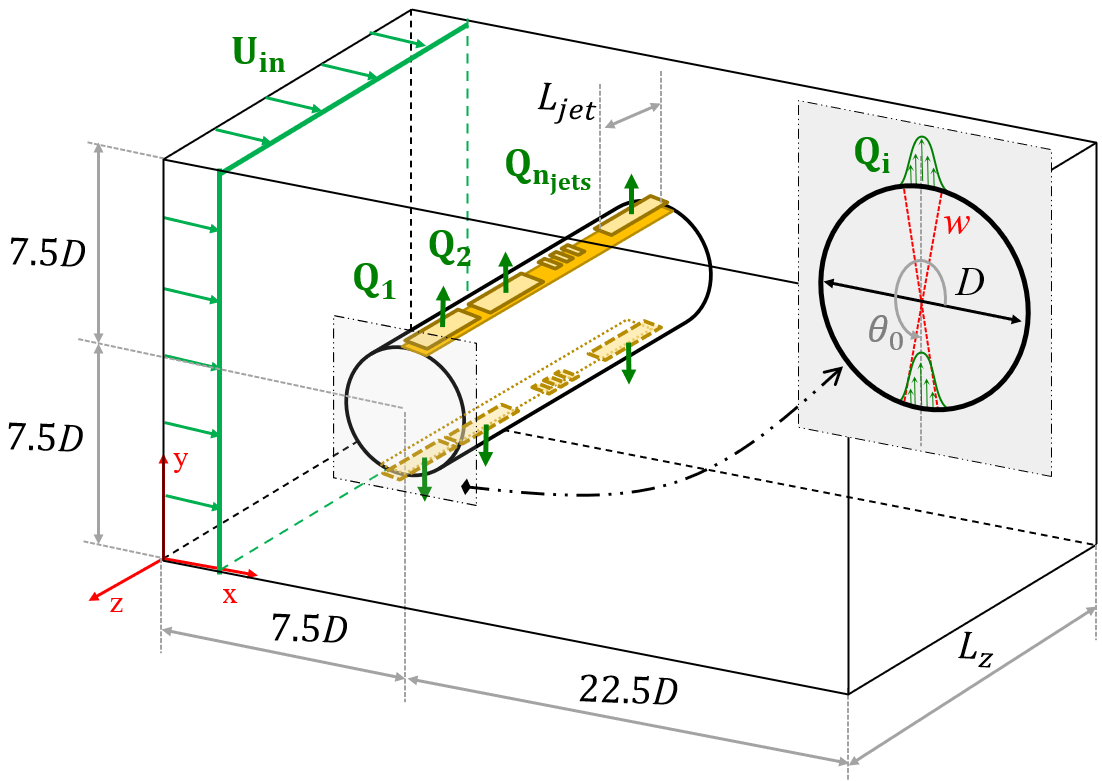
- Alya CFDソルバー(有限要素法ナビエ-ストークス)とマルチエージェントPPOフレームワークを組み合わせる。
- 質量流量Qでスパンウェイズジェットを制御する複数の独立エージェントを、ニューロンネットワークの重みを共有して展開する。
- ドラッグ低減と揚力ペナルティに基づく局所および全体報酬を、βパラメータ(β=0.8)で調整する。
- 疑似環境ごとに85プローブのスライスで尾部の状態を観測し、近接プローブを用いて255プローブ観測を形成することも可能とする。
- Qスケーリングを用いてQ_max3D = 2 * Q_max2Dとしてポリシー出力をジェット作動にマッピングし、環境ごとに相反するジェット動作を課すことでゼロネット質量流を保証する。
実験結果
リサーチクエスチョン
- RQ1局所的に動作するエージェントを用いたMARLは、3D円柱上の複数表面ジェットを制御して、さまざまなレイノルズ数でドラッグを低減できるか。
- RQ2近接尾部観測と異なるスパンウェイ領域サイズを取り入れることが、学習と性能にどのように影響するか。
- RQ32Dベンチマークと比較して3Dでどの程度のドラッグ低減性能が達成され、尾部渦の動力学がポリシー戦略にどのように影響するか。
主な発見
| Re | 2Dベンチマーク | W85 | N85 | N255 |
|---|---|---|---|---|
| 100 | 13.0 | 9.4 | 4.3 | 8.0 |
| 200 | 14.9 | 17.2 | 11.1 | 12.7 |
| 300 | 21.9 | 6.7 | 10.8 | 15.3 |
| 400 | 5.6 | 9.9 | 15.1 | 11.1 |
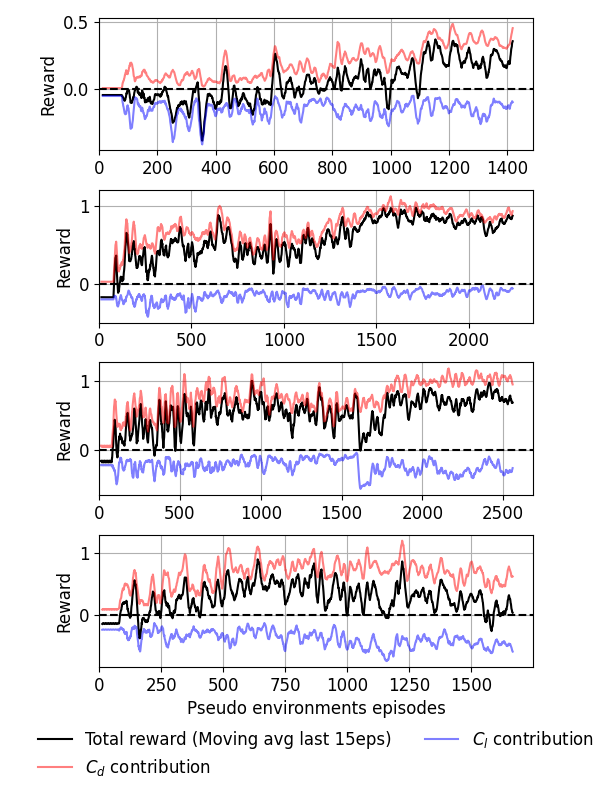
- MARLは、Re = 100, 200, 300, 400で3D円柱ケースにおいてドラッグの有意な低減を達成し、Ljet/D = 1のときの値はそれぞれ9.4%、17.2%、6.7%、9.9%である。
- ジェットが短い場合(Ljet/D = 0.4)、局所観測ではドラッグ低減が4.3%、11.0%、10.8%、15.0%、近傍観測が8.0%、12.7%、15.2%、11.0%である。
- 3Dの結果は、2Dと比べて高いReでより一貫したドラッグ低減性能を示すが、Re依存のばらつきもある。
- DRL制御は渦 sheddingの強度を緩和し、尾部の再接着を遅らせることを示しており、アクチュエーションによる尾部渦の安定化効果を示唆する。
- ポリシーはスパン全体で抽出された、同期したジェット戦略を示しており、高いReではジェット長と観測粒度を変えることで利益が得られる可能性がある。
- MARLフレームワークは、重みを共有した疑似環境での訓練を可能にし、学習を加速させ、概念的には異なる円柱幾何にも転移可能である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。