[論文レビュー] Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
本研究は、適応された大規模言語モデル(LLMs)が、文脈内学習と微調整の両方の方法を用いて、複数の臨床要約タスクにおいて医療専門家の要約と同等またはそれを上回ることができることを示しており、安全性分析も含まれている。
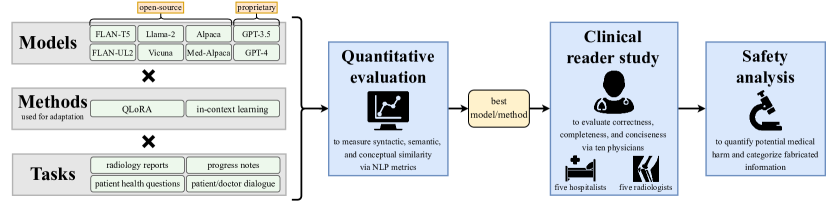
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
研究の動機と目的
- 適応されたLLMsが高品質な臨床要約を作成できるか評価することで、臨床医の文書化負担を軽減する。
- モデルタイプ、適応方法、タスク間の性能トレードオフを評価する。
- LLM生成の要約が医療専門家の要約に劣らない、あるいはそれを上回るかを検証する。
- 臨床利用で有害となり得る安全性への影響やエラータイプを検討する。
提案手法
- 6つのデータセットを用いて、4つの臨床要約タスクで8つのLLM(オープンソースのseq2seqおよび自己回帰モデル、ならびに商用モデル)を評価する。
- 2つの適応方法を適用する:最も近傍の取得例を用いた文脈内学習(ICL)と、量子化された低ランク適応(QLoRA)によるファインチューニング。
- タスク固有の専門知識と長さの制約を含むようにプロンプトを調整する;モデルの温度を0.1に設定。
- 評価にはNLP指標(BLEU、ROUGE-L、BERTScore、MEDCON)とQuickUMLSベースの概念チェックを使用する。
- 最良モデルの要約と医療専門家の要約を比較するため、10人の医師を対象に臨床読者研究を実施する。
- エラーを潜在的な有害性と結びつけ、偽情報を分類する安全性分析を実施する。
実験結果
リサーチクエスチョン
- RQ1適応されたLLMは複数の臨床タスクで医療専門家と同等以上の臨床要約を生成できるか。
- RQ2放射線科、患者の質問、進行ノート、対話要約で最も高い性能を発揮するモデルタイプと適応方法の組み合わせはどれか。
- RQ3NLP指標のスコアと臨床読者の好みはタスクを通じてどのように相関するか。
- RQ4LLM生成の臨床要約に関連する安全性の考慮事項とエラータイプ(潜在的な有害性や偽情報を含む)は何か。
主な発見
- 最高のパフォーマンス設定: 文脈内学習を用いたGPT-4は、要約の完全性と正確さの点で医療専門家の要約をしばしば上回る。
- 適応方法の選択にはトレードオフがある;十分な文脈内の例があれば、文脈内学習はファインチューニング済みモデルに匹敵またはそれを超える。
- QLoRAを用いたオープンソースモデルは一部のベースラインを上回ることがあるが、商用モデル(GPT-3.5、GPT-4)は、十分な文脈内例があれば一般により強力な結果を達成する。
- 臨床読者研究:放射線科、患者の質問、進行ノートにおいて、モデルの要約は医療専門家に比べ81%のケースで好まれるまたは劣らない(非劣性45%、好ましい36%)と評価された。
- 安全性分析は、LLMと医療専門家の双方に課題を明らかにし、エラーは潜在的な医療有害性に関連し、偽情報のタイプが分類される。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。