[論文レビュー] Advancing GenAI Assisted Programming--A Comparative Study on Prompt Efficiency and Code Quality Between GPT-4 and GLM-4
本研究は GenAI を用いたプログラミングにおいて GPT-4 と GLM-4 を比較し、単純なプロンプトが最良のコード生成をもたらすこと、事前の確認ステップが成功を高めること、GPT-4 が全体的に GLM-4 よりわずかに上回ること、そして GenAI が従来の水準より 30–100×のコーディング効率を向上させる可能性があることを示している。
This study aims to explore the best practices for utilizing GenAI as a programming tool, through a comparative analysis between GPT-4 and GLM-4. By evaluating prompting strategies at different levels of complexity, we identify that simplest and straightforward prompting strategy yields best code generation results. Additionally, adding a CoT-like preliminary confirmation step would further increase the success rate. Our results reveal that while GPT-4 marginally outperforms GLM-4, the difference is minimal for average users. In our simplified evaluation model, we see a remarkable 30 to 100-fold increase in code generation efficiency over traditional coding norms. Our GenAI Coding Workshop highlights the effectiveness and accessibility of the prompting methodology developed in this study. We observe that GenAI-assisted coding would trigger a paradigm shift in programming landscape, which necessitates developers to take on new roles revolving around supervising and guiding GenAI, and to focus more on setting high-level objectives and engaging more towards innovation.
研究の動機と目的
- GPT-4 vs GLM-4 との横断比較を通じて、GenAI をプログラミングツールとして使用する際のベストプラクティスを評価する。
- プロンプトの複雑さがコード生成の品質と成功に与える影響を判定する。
- CoTに類似した事前の確認が生成成功に与える影響を評価する。
- GenAI支援のコーディングワークフローに関する一般的なガイドラインと洞察を提供する。
提案手法
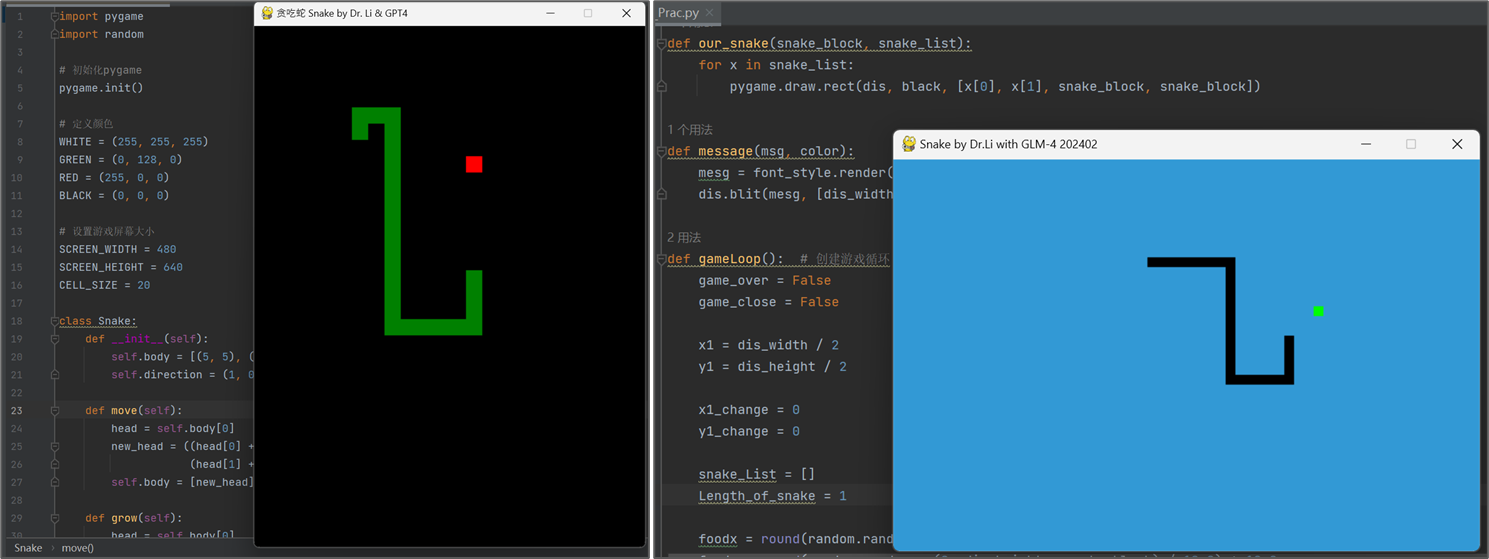
- LLMを比較するための統制されたコーディング課題としてゲーム Snake を使用する。
- コード生成を探るため、複雑さを増す4つのワンショットプロンプトレベルを設計する。
- 評価基準を設定する:成功率、デバッグ効率、コードの読みやすさ、機能の豊富さ。
- 反復的なデバッグと改善をシミュレートするフォローアップ prompting ループを実装する。
- プロンプトと対話全体で240の結果を収集し、統計分析を行う。
- GPT-4とGLM-4の間でのコード生成戦略の差(例:ライブラリの選択)を分析する。
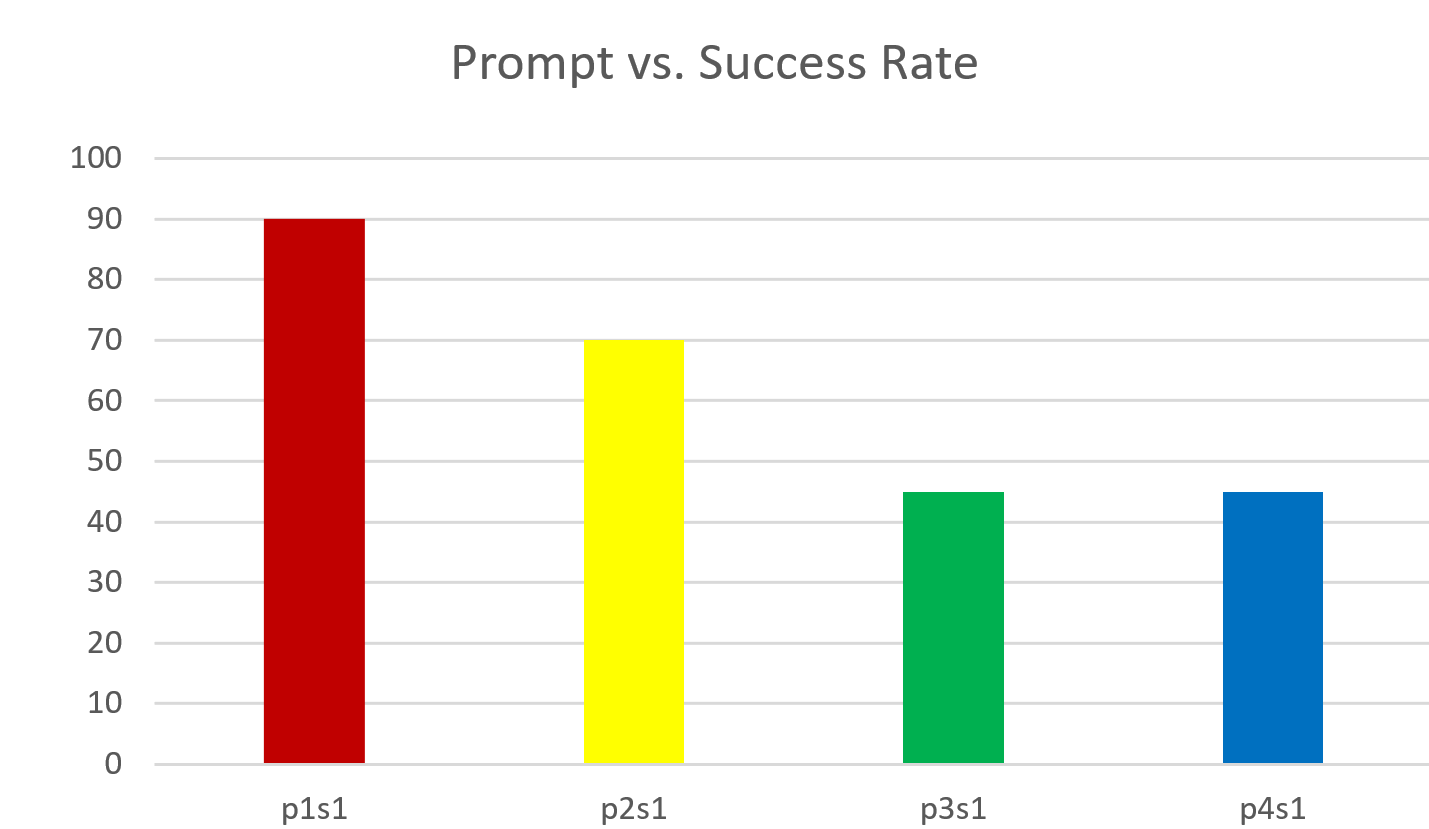
実験結果
リサーチクエスチョン
- RQ1プロンプトの複雑さは GPT-4 と GLM-4 のワンショットコード生成成功にどのように影響するか?
- RQ2CoT に類似した事前確認は GenAI支援のコード生成の成功と効率を改善するか?
- RQ3Pythonベースのゲームコーディング課題における GPT-4 と GLM-4 の相対的な強みと弱みは何か?
- RQ4コード品質(読みやすさ、完成度、正確さ)はモデルとプロンプトレベルでどう比較されるか?
主な発見
- 最も簡単なプロンプト(Prompt 1)がワンショットで最高の成功率を達成する(GPT-4 と GLM-4)。
- 事前確認ラウンドはワンショットの成功率を大幅に高め、Chain-of-Thought の利点と一致する。
- GPT-4 は全体的に GLM-4 を僅差で上回るが、最も複雑なプロンプトでは GLM-4 が同等の成功に達することがある。
- GLM-4 はしばしば Type 2 の故障(不完全または切り捨てられたコード)を示し、特定のライブラリ(例:Pygame)に依存しがちである。
- 簡略化されたモデルでは、GenAI支援コードは従来の標準に対して30–100倍のコーディング効率の向上が示唆されている。
- GenAI プロンプトの進展により初心者が短時間で機能する Snake ゲームを開発できるようになり、アプローチの持ち運びやすさとアクセス性を示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。