[論文レビュー] Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
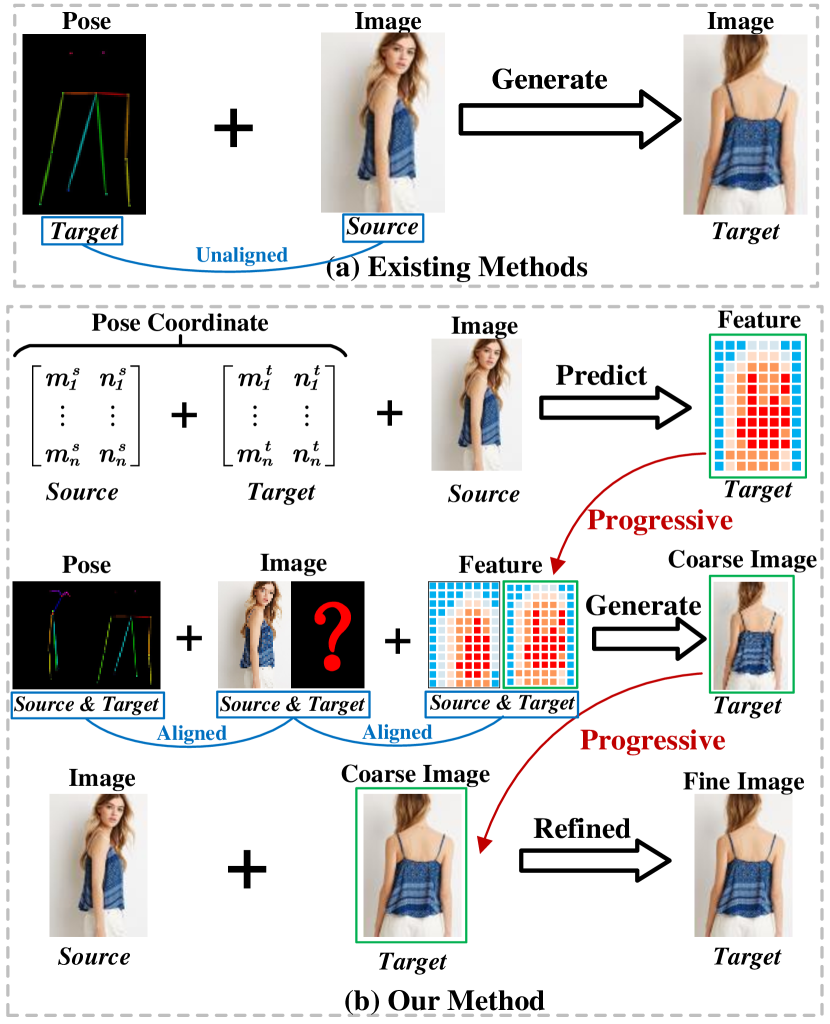
PCDMs は、 pose-guided person image synthesis のために source および target pose を橋渡しする三段階の段階的拡散フレームワークを導入し、現実感と一貫性を向上させる。
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/tencent-ailab/PCDMs.
研究の動機と目的
- source と target pose が異なる場合の pose-guided person image synthesis の改善を動機付ける。
- appearance、pose、および texture を段階的に整合させる三段階拡散フレームワークを提案する。
- global feature、dense correspondence、texture refinement を活用してフォトリアリズムを高める。
- 公開データセットでの定量・定性的結果の優位性を示し、下流タスクを評価する。
提案手法
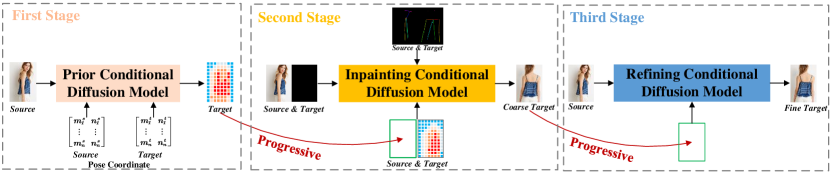
- Stage 1: Prior conditional diffusion model predicts the target image global features from pose coordinates and source image using a transformer and CLIP-based embeddings.
- Stage 2: Inpainting conditional diffusion model uses global target features to establish dense source-target correspondences and generate a coarse-skeleton image.
- Stage 3: Refining conditional diffusion model uses the coarse image to restore textures and fine details via texture-guided diffusion with cross-attention.
- Classifier-free guidance is employed to balance fidelity and diversity; latent diffusion and CLIP-based embeddings are leveraged.
- Three-stage progression converts unaligned input generation into aligned, high-quality synthesis.
実験結果
リサーチクエスチョン
- RQ1Can a three-stage progressive diffusion framework effectively bridge the gap between source and target poses for person image synthesis?
- RQ2Do global feature prediction, dense correspondence, and texture refinement yield improvements over single-stage approaches?
- RQ3How does PCDMs perform on standard benchmarks and in downstream tasks like person re-identification?
主な発見
| Dataset | Methods | SSIM (↑) | LPIPS (↓) | FID (↓) |
|---|---|---|---|---|
| DeepFashion (256×176) | Def-GAN | 0.6786 | 0.2330 | 18.457 |
| DeepFashion (256×176) | PATN | 0.6709 | 0.2562 | 20.751 |
| DeepFashion (256×176) | ADGAN | 0.6721 | 0.2283 | 14.458 |
| DeepFashion (256×176) | PISE | 0.6629 | 0.2059 | 13.610 |
| DeepFashion (256×176) | GFLA | 0.7074 | 0.2341 | 10.573 |
| DeepFashion (256×176) | DPTN | 0.7112 | 0.1931 | 11.387 |
| DeepFashion (256×176) | CASD | 0.7248 | 0.1936 | 11.373 |
| DeepFashion (256×176) | NTED | 0.7182 | 0.1752 | 8.6838 |
| DeepFashion (256×176) | PIDM | 0.7312 | 0.1678 | 6.3671 |
| DeepFashion (256×176) | PCDMs (Ours) | 0.7444 | 0.1365 | 7.4734 |
| DeepFashion (512×352) | CocosNet2 | 0.7236 | 0.2265 | 13.325 |
| DeepFashion (512×352) | NTED | 0.7376 | 0.1980 | 7.7821 |
| DeepFashion (512×352) | PIDM | 0.7419 | 0.1768 | 5.8365 |
| DeepFashion (512×352) | PCDMs (Ours) | 0.7601 | 0.1475 | 7.5519 |
| Market-1501 | Def-GAN | 0.2683 | 0.2994 | 25.364 |
| Market-1501 | PTN | 0.2821 | 0.3196 | 22.657 |
| Market-1501 | GFLA | 0.2883 | 0.2817 | 19.751 |
| Market-1501 | DPTN | 0.2854 | 0.2711 | 18.995 |
| Market-1501 | PIDM | 0.3054 | 0.2415 | 14.451 |
| Market-1501 | PCDMs (Ours) | 0.3169 | 0.2238 | 13.897 |
- PCDMs achieve higher SSIM and lower LPIPS on DeepFashion and Market-1501 compared to several SOTA methods.
- On DeepFashion 256x176, PCDMs achieve SSIM 0.7444, LPIPS 0.1365, FID 7.4734, outperforming many baselines.
- On DeepFashion 512x352, PCDMs achieve SSIM 0.7601, LPIPS 0.1475, FID 7.5519, exceeding several competitors.
- On Market-1501, PCDMs achieve SSIM 0.3169, LPIPS 0.2238, FID 13.897, surpassing multiple methods.
- User studies indicate favorable real-image misclassification rates and preferences for PCDMs.
- Refining diffusion improves results across other SOTA methods, showing universality.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。