[論文レビュー] Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
本論文は拡散モデルの敵対的サンプルを定義し、入力絵画を撹乱するAdvDMを提案して、DMベースのアートAIが特徴を抽出したりスタイルを模倣したりできないようにする。評価はモンテカルロに基づく最適化と複数の著作権保護シナリオで行われた。
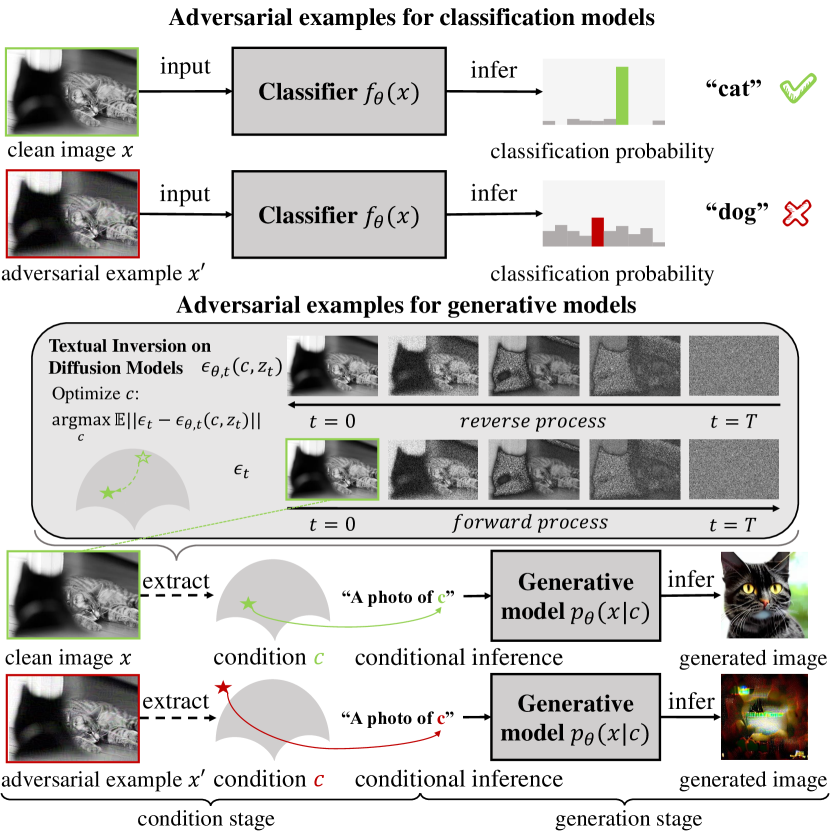
Recently, Diffusion Models (DMs) boost a wave in AI for Art yet raise new copyright concerns, where infringers benefit from using unauthorized paintings to train DMs to generate novel paintings in a similar style. To address these emerging copyright violations, in this paper, we are the first to explore and propose to utilize adversarial examples for DMs to protect human-created artworks. Specifically, we first build a theoretical framework to define and evaluate the adversarial examples for DMs. Then, based on this framework, we design a novel algorithm, named AdvDM, which exploits a Monte-Carlo estimation of adversarial examples for DMs by optimizing upon different latent variables sampled from the reverse process of DMs. Extensive experiments show that the generated adversarial examples can effectively hinder DMs from extracting their features. Therefore, our method can be a powerful tool for human artists to protect their copyright against infringers equipped with DM-based AI-for-Art applications. The code of our method is available on GitHub: https://github.com/mist-project/mist.git.
研究の動機と目的
- 人間が創作した絵画を拡散モデルベースのAIアートから守るための著作権保護を動機付ける。
- 拡散モデル(DMs)における敵対的サンプルの形式的な枠組みを定義する。
- DMの特徴抽出を妨げるようモンテカルロ推定で敵対的入力を生成するAdvDMを設計する。
- Latent Diffusion Models (LDMs) 上で、 テキストから画像、スタイル転送、画像から画像の各シナリオでAdvDMを評価する。
- AdvDMに対するロバスト性と防御戦略を、前処理防御を含め評価する。
提案手法
- 拡散モデルの敵対的サンプルを x' = x + delta、||delta|| <= epsilon として、潜在拡散ステップをモンテカルロで回して p_theta(x+delta) を最小化する。
- 勾配上昇法を用いて、後方分布のような分布から抽出された潜在変数 x'1:T のサンプルで平均化したDM訓練損失を最大化することで delta を最適化する。
- AdvDMを用いる: 潜在変数のモンテカルロサンプリング(Nサンプル)で目的関数を推定する、反復的な符号付き勾配ステップ。
- テキストから画像、スタイル転送、画像から画像のタスクで条件付き生成指標(FID、Precision、Recall)を用いて評価する。
- サンプリングステップ、摂動予算、推論時間のトレードオフを検討し、前処理防御(JPEG、TVM、SR)および浄化(DiffPure)と比較する。
- 主要方程式: p_theta(x) = ∫ p_theta(x0:T) dx1:T; 敵対的目的関数 max_delta E_{x1:T'~u(x1:T')} L_DM(theta) = -log p_theta(x0:T) (Eq. 7); AdvDM更新: x0^(i+1) = x0^(i) + alpha * sgn(∇_{x0^(i)} L_DM(...)) (Eq. 9).
実験結果
リサーチクエスチョン
- RQ1敵対的摂動は、絵画を模倣するために用いられる条件付け特徴(例:テキスト反転プロンプト)の抽出を拡散モデルから妨げることができるか?
- RQ2摂動入力に条件付けられた DM 生成出力の品質を複数の生成シナリオで低下させるために AdvDM はどの程度効果的か?
- RQ3DM の敵対的サンプルを生成する際の実用的なトレードオフ(サンプリングステップ、摂動予算、推論時間)は何か?
- RQ4前処理防御は AdvDM を画像の意味を壊さずに適切に緩和できるか?
- RQ5AdvDM は商用 DM システム(例: Stable Diffusion)や様々な条件付けパラダイム(テキスト、スタイル、画像)へ拡張できるか?
主な発見
| データセット | 指標 | LSUN-Cat FID | LSUN-Cat prec. | LSUN-Cat recall | LSUN-Sheep FID | LSUN-Sheep prec. | LSUN-Sheep recall | LSUN-Airplane FID | LSUN-Airplane prec. | LSUN-Airplane recall |
|---|---|---|---|---|---|---|---|---|---|---|
| LSUN-Cat | No attack | 34.94 | 0.5643 | 0.1531 | 32.81 | 0.6378 | 0.1228 | 39.22 | 0.5016 | 0.2765 |
| LSUN-Cat | AdvDM | 127.04 | 0.1708 | 0.061 | 203.5 | 0.0058 | 0.378 | 169.67 | 0.0263 | 0.3235 |
- 敵対的な入力で条件付けられたテキストから画像生成において、敵対的サンプルはFIDを著しく悪化させ、Precisionを低下させることがあり、作品特徴の保護が成功していることを示す。
- AdvDMはスタイル転送および画像から画像のシナリオにおけるサンプル品質の低下として、DMがスタイル/内容を模倣する能力を著しく低下さる。
- モンテカルロサンプルを増やすと攻撃の効果が向上する(FIDが高くPrecisionが低下)、ただし推論時間が増えるため、主要実験では40サンプリングステップのバランスを取った。
- 摂動予算が4/255程度でも生成品質に意味ある影響を与え、より大きな予算は効果を強くするが実行時間も長くなる。
- JPEGやTVMのような前処理防御はAdvDMを部分的にしか緩和せず、SR防御はFIDにはより効果があるがPrecisionには一貫して効果がない、AdvDMによる意味的破壊が持続していることを示す。
- この手法はテキスト的反転ベースの条件付けに対して効果的であり、WikiArtやLSUNデータセットでの評価を含む複数のDMベースのアート生成ワークフローに一般化される。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。