[論文レビュー] Agent AI: Surveying the Horizons of Multimodal Interaction
エージェントAIを提案する包括的な調査—大規模基盤モデル(LLMs/VLMs)から構築されたマルチモーダルで具現化されたエージェントが、物理環境と仮想環境の両方を知覚、推論、行動することを示し、学習パラダイム、倫理、応用について議論する。
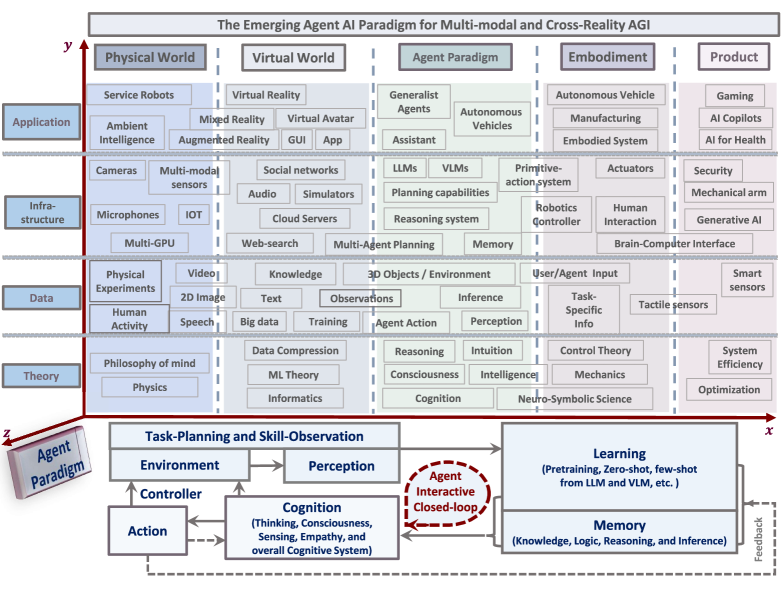
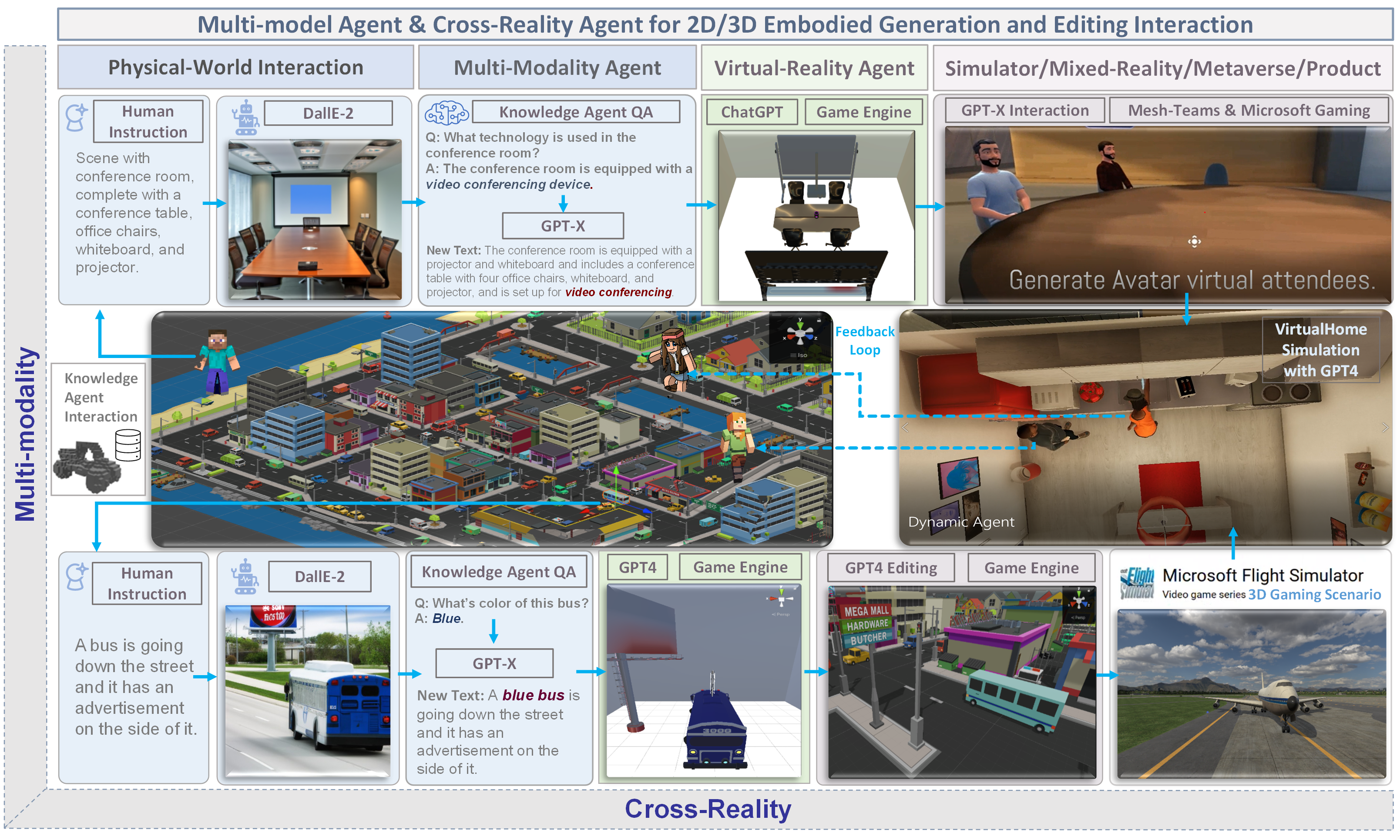
Multi-modal AI systems will likely become a ubiquitous presence in our everyday lives. A promising approach to making these systems more interactive is to embody them as agents within physical and virtual environments. At present, systems leverage existing foundation models as the basic building blocks for the creation of embodied agents. Embedding agents within such environments facilitates the ability of models to process and interpret visual and contextual data, which is critical for the creation of more sophisticated and context-aware AI systems. For example, a system that can perceive user actions, human behavior, environmental objects, audio expressions, and the collective sentiment of a scene can be used to inform and direct agent responses within the given environment. To accelerate research on agent-based multimodal intelligence, we define "Agent AI" as a class of interactive systems that can perceive visual stimuli, language inputs, and other environmentally-grounded data, and can produce meaningful embodied actions. In particular, we explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback. We argue that by developing agentic AI systems in grounded environments, one can also mitigate the hallucinations of large foundation models and their tendency to generate environmentally incorrect outputs. The emerging field of Agent AI subsumes the broader embodied and agentic aspects of multimodal interactions. Beyond agents acting and interacting in the physical world, we envision a future where people can easily create any virtual reality or simulated scene and interact with agents embodied within the virtual environment.
研究の動機と目的
- 視覚的、言語的、環境データを知覚し、具現化された行動を生み出す相互作用系の一類として、エージェントAIを定義する。
- 大規模基盤モデル(LLMsおよびVLMs)とエージェント機能の統合が、クロスリアリティ環境での操作にどう適用されるかを調査する。
- ゲーミング、ロボティクス、ヘルスケアなどの領域におけるエージェントの種類と応用を分類する。
- 強化学習、模倣学習、インコンテキスト学習といった学習戦略およびゼロショット/少数ショットの状況に対応するエージェント基盤について論じる。
- エージェントベースのAIに関する倫理、プライバシー、バイアス、解釈可能性、ガバナンスの検討事項に対処する。
提案手法
- LLMs/VLMsと具現化された行動を統合するエージェントAIシステムの訓練と評価のフレームワークを提案する。
- 基盤モデル駆動のエージェントにおける幻覚とバイアスの課題を分析し、 grounding(グラウンディング)および情報検索強化手法を検討する。
- マルチドメインエージェントのためのエージェント・トランスフォーマーのパラダイムと構築プロセスを概説する。
- 学習戦略(RL、IL、インコンテキスト学習)を説明し、それらがタスク間でのゼロショットおよび少数ショットの一般化をどう可能にするかを示す。
- エージェントの種類、モダリティ、実環境/仮想環境を整理した分類法と、評価ベンチマークやデータセットを提示する。
実験結果
リサーチクエスチョン
- RQ1LLMsとVLMsを活用して、物理的・仮想的な設定の両方で効果的に動作する具現化されたマルチモーダルエージェントをどのように創出できるか。
- RQ2一般化、グラウンディング、堅牢性を跨ぐエージェントAIをサポートする最適な学習パラダイムとアーキテクチャは何か。
- RQ3研究と評価を導くために、能力、モダリティ、環境でエージェントAIをどう分類すべきか。
- RQ4エージェントベースのシステムに関する倫理、プライバシー、包括性の考慮事項は何で、それらをどう緩和できるか。
- RQ5マルチモーダルなエージェントAI研究を進めるために、どのデータセットとベンチマークが必要か。
主な発見
- エージェントAIは、物理的現実と仮想現実の両方にわたる、よりインタラクティブで具現化されたマルチモーダル知性への道として位置づけられる。
- 一般家、具現化、シミュレーション、生成、知識、神経シンボリックなどを含む、エージェントAIのカテゴリと応用の総合的な分類法が提供される。
- 基盤モデルとの統合の議論は、幻覚、バイアス、データのプライバシー、解釈可能性の検討事項を含む、利点とリスクを強調する。
- 本論文は、ゼロショットおよび少数ショットの一般化のための学習戦略(RL、IL、インコンテキスト学習)とエージェント基盤を概説する。
- 倫理的・社会的・ガバナンスの側面が分析され、Agent AIの進展を評価するためのデータセットとリーダーシップボードが提案される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。