[論文レビュー] AI-assisted coding: Experiments with GPT-4
GPT-4は実用的なコードを生成し、リファクタリングを通じて可読性を改善できるが、テストの正確性と信頼性のためには人間による検証が依然として不可欠である。GPT-4が生成したテストはしばしば失敗し、デバッグが必要となる。
Artificial intelligence (AI) tools based on large language models have acheived human-level performance on some computer programming tasks. We report several experiments using GPT-4 to generate computer code. These experiments demonstrate that AI code generation using the current generation of tools, while powerful, requires substantial human validation to ensure accurate performance. We also demonstrate that GPT-4 refactoring of existing code can significantly improve that code along several established metrics for code quality, and we show that GPT-4 can generate tests with substantial coverage, but that many of the tests fail when applied to the associated code. These findings suggest that while AI coding tools are very powerful, they still require humans in the loop to ensure validity and accuracy of the results.
研究の動機と目的
- 最小のプロンプト工夫でインタラクティブなデータサイエンスのコーディング作業におけるGPT-4の性能を評価する。
- 既存のPythonコードのリファクタリングと品質向上能力を評価する。
- 自分のコードのテストを生成し、得られるテスト網羅性を検証する能力を調査する。
- 科学研究者にとってのAIコーディングアシスタントの総合的な有用性と限界を評価する。
提案手法
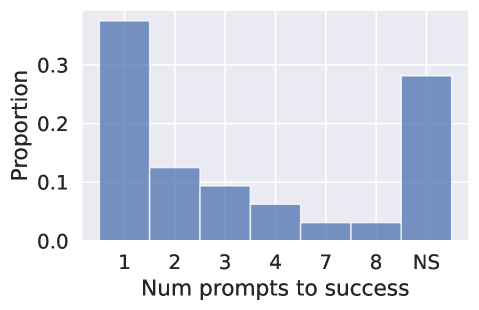
- データサイエンス問題に関するGPT-4を用いた対話型コード生成;コードの修正と完成のために複数のプロンプトを使用;各問題あたりおよそ5分程度で成功を判断。
- 品質と関連性でフィルタリングされたGitHubの候補ファイル274件のデータセットを用いたGPT-4による既存Pythonコードのリファクタリング;静的解析と保守性指標でコード品質を評価。
- 自動化されたテスト生成:GPT-4が複数のドメイン向けにコードとテストを生成するプロンプトを作成;Coverage.pyとpytestを用いて実行可能性とテスト網羅性を評価するスクリプトを実行。
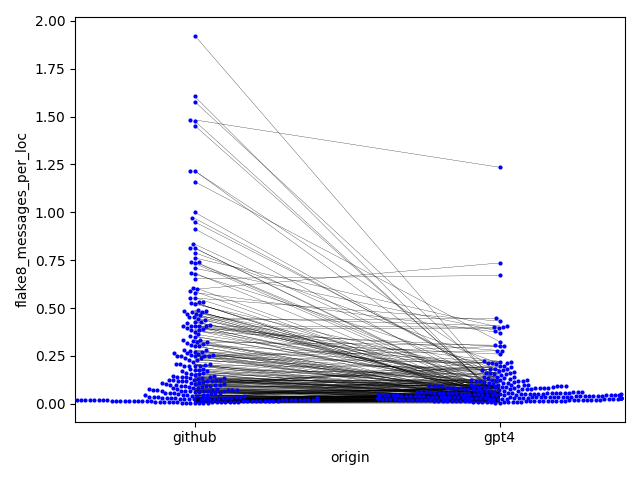
- 元のコードとリファクタリング後のコードを、可読性・保守性・複雑さ・スタイルの指標で比較する定量的比較(flake8とradonパッケージを使用);FDR補正付きの対応のあるt検定などの統計検定で差を報告。
- 制約の評価:誤った出力や幻視的出力の分析、人間の検証の必要性、将来の課題としての prompting 技法(例:思考の連鎖)についての議論。
実験結果
リサーチクエスチョン
- RQ1最小限のプロンプト設計と人間の指導で、GPT-4はデータサイエンス問題に対して動作するPythonコードを生成できるか。
- RQ2挙動を変更せずに、既存のコードをリファクタリングして可読性と保守性を向上させることがGPT-4にできるか。
- RQ3自分のコードに対して高い網羅性を持つテストを生成できるか、またこれらのテストはどれくらいの頻度で失敗したりデバッグを必要とするか。
- RQ4研究者にとってのAIコーディングアシスタントとしてのGPT-4の総合的な有用性と限界は何か。
主な発見
| 指標 | GitHub 中央値 | GPT-4 中央値 | コーエンのd | P値(FDR) |
|---|---|---|---|---|
| Maintainability index | 70.285 | 74.092 | 0.33 | <.001 |
| Halstead bugs | 0.081 | 0.068 | 0.13 | 0.045 |
| Halstead difficulty | 3.214 | 3.089 | 0.16 | 0.012 |
| flake8 messages per line | 0.237 | 0.089 | 0.50 | <.001 |
| Mean cyclomatic complexity | 3.462 | 3.284 | 0.18 | 0.006 |
| Number of comments | 7.81 | 7.086 | 0.08 | 0.196 |
| Logical lines of code | 46.022 | 43.372 | 0.27 | <.001 |
- 試行の72%(23/32)はGPT-4で成功したコード成果を生み出し、最初のプロンプトで成功したのは37.5%(12/32)。
- リファクタリング後のコードは1行あたりのflake8メッセージが大幅に減少(0.23対0.09)、標準遵守と可読性の改善を示す(Cohen’s d = 0.50)。
- コード品質指標はリファクタリング後に改善:保守性指数、Halstead指標、サイクロマティック複雑度は平均的に改善(小〜中程度の効果量、FDR後p < .05)。
- GPT-4は自分のコードに対して高い網羅性のテストを生成したが、統合後に100件中45件のみが通過。多くのテストは不適切な仮定や文脈不足により失敗。
- ほとんどのスクリプト(97/100)はエラーなく実行されたが、テストとコードの不整合を解消するために大きなデバッグが必要だった。
- この研究は、GPT-4を用いても正確さのためには人間の関与が依然として不可欠であり、特に数学的・領域特有の側面においてそうであることを強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。