[論文レビュー] AI for Biomedicine in the Era of Large Language Models
本論文は、大規模言語モデルをテキスト、 生物学的配列、脳信号という3つの生物医療データタイプに跨って適用する方法を概観し、信頼性、個別化、多モーダル統合などの課題について論じる。
The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation
研究の動機と目的
- 生物医薬知識発見のために、テキストデータ・生物学的配列・脳信号の三つのデータモダリティに跨る大規模言語モデルの探索を促す。
- データモダリティごとに適した既存の生物医薬用LLMとアーキテクチャを調査する。
- 信頼性・個別化・マルチモーダルな生物医薬AIに関する課題と考慮事項を特定する。
- 臨床および研究の場で生物医薬用LLMsが可能にする応用と下流タスクを強調する。
提案手法
- 三つのデータカテゴリ(テキストデータ、生物学的配列、脳信号)にまたがる生物医薬用LLMの文献をレビューし、統合する。
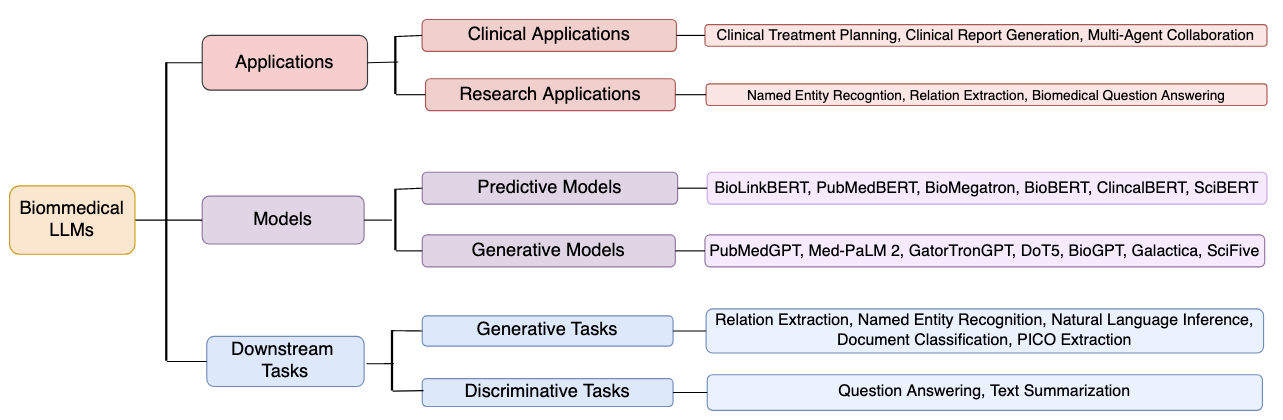
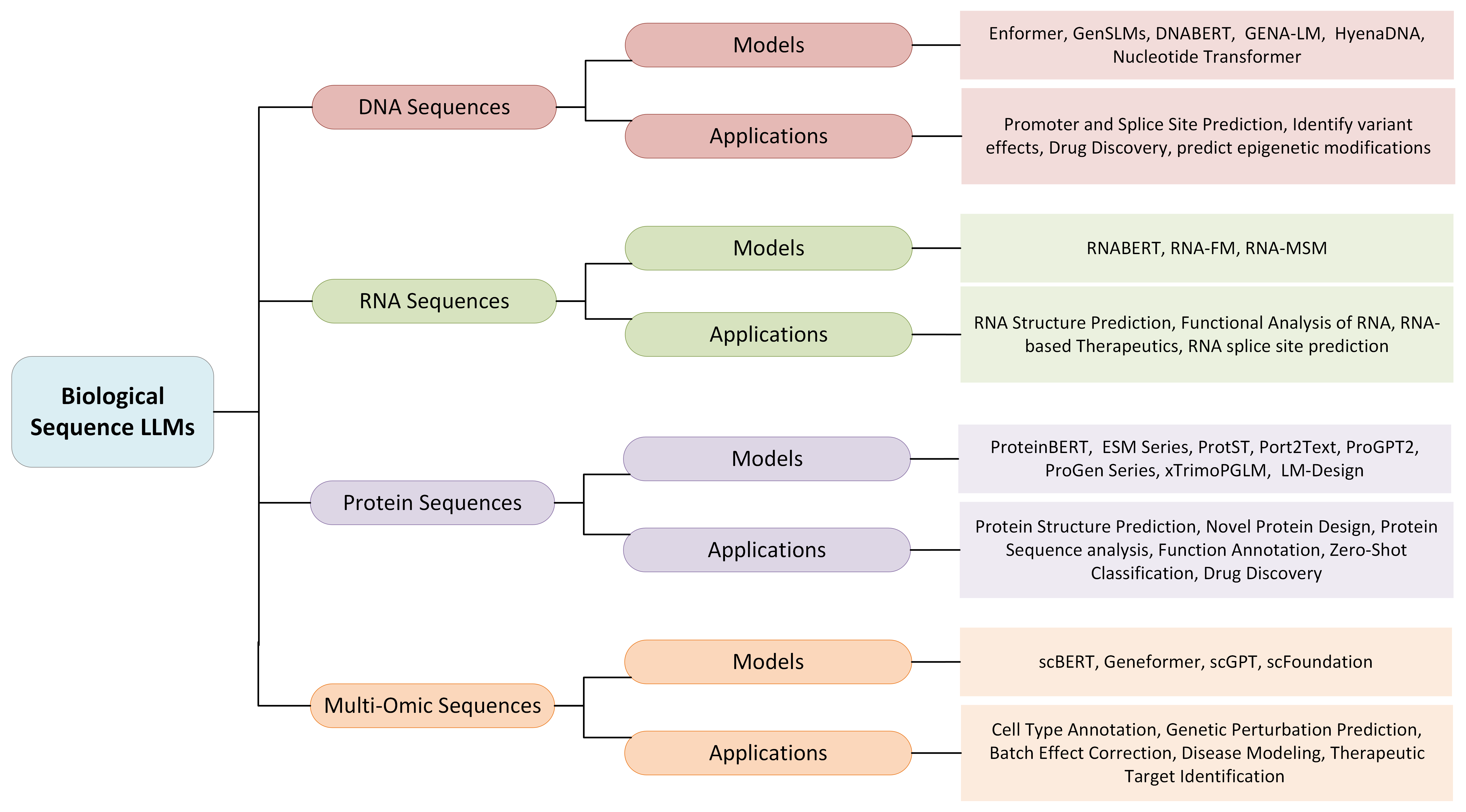
- 各モダリティの代表的なモデルと事前学習戦略を要約する(例:SciBERT、BioBERT、BioGPT、GenSLMs、DNABERT、RNABERT、ESM、 ProtST など)。
- 情報抽出、質問応答、関係抽出、タンパク質/RNA配列の理解と生成などの応用を論じる。
- 信頼性、個別化、マルチモーダルデータ表現を含む課題を概説する。
実験結果
リサーチクエスチョン
- RQ1生物医薬テキストデータ、配列、脳信号に適用したLLMの現状の能力と限界は何か。
- RQ2各生物医薬データモダリティに対して最も効果的なモデルと事前学習手法は何か。
- RQ3信頼性が高く、個別化され、マルチモーダルなLLM主導の生物医薬研究と実践を実現するには、どのような課題に対処すべきか。
主な発見
- 生物医薬用LLMは、テキストデータ、配列(DNA、RNA、タンパク質、多オミクス)、および脳信号に跨り、専門的なモデルと事前学習レジームを備えている。
- SciBERT、BioBERT、PubMedBERT、BioLinkBERT、Galactica、BioGPT、DoT5、GenSLMs、DNABERT、RNABERT、RNA-MSM、ESM/ESM-2、ProtST など、三つのデータカテゴリ全体で多様なタスクにおいて最先端またはほぼ最先端の性能を達成している。
- 応用には情報抽出、質問応答、関係抽出、そして生物医薬発見のための高度な配列/機能予測と設計が含まれる。
- 本論文は、信頼性の確保、個別化の推進、マルチモーダルな生物医薬データへの適応といった課題を強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。