[論文レビュー] Aligning Large Multimodal Models with Factually Augmented RLHF
この論文は強化学習を人間のフィードバックから学ぶ(RLHF)を大規模多模態モデル(LMMs)に適用し、Factually Augmented RLHF(Fact-RLHF)を導入して、報酬信号に事実的手掛かり(キャプション、正解オプション)を組み込むことで幻覚を減らし、さらに高品質なビジョン指示チューニングデータと新しいMMHal-Bench評価ベンチマークを提供します。
Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misalignment issue, we adapt the Reinforcement Learning from Human Feedback (RLHF) from the text domain to the task of vision-language alignment, where human annotators are asked to compare two responses and pinpoint the more hallucinated one, and the vision-language model is trained to maximize the simulated human rewards. We propose a new alignment algorithm called Factually Augmented RLHF that augments the reward model with additional factual information such as image captions and ground-truth multi-choice options, which alleviates the reward hacking phenomenon in RLHF and further improves the performance. We also enhance the GPT-4-generated training data (for vision instruction tuning) with previously available human-written image-text pairs to improve the general capabilities of our model. To evaluate the proposed approach in real-world scenarios, we develop a new evaluation benchmark MMHAL-BENCH with a special focus on penalizing hallucinations. As the first LMM trained with RLHF, our approach achieves remarkable improvement on the LLaVA-Bench dataset with the 94% performance level of the text-only GPT-4 (while previous best methods can only achieve the 87% level), and an improvement by 60% on MMHAL-BENCH over other baselines. We opensource our code, model, data at https://llava-rlhf.github.io.
研究の動機と目的
- LMMsにおける多模態のミスアラインメントと幻覚への動機づけと対処。
- 視覚言語タスクに適応したRLHFベースの整列パイプラインを提案。
- 報酬を事実情報で校正するFactually Augmented RLHFを導入。
- 高品質な人間アノテーション付き多模態データで視覚指示チューニングデータを強化。
- 幻覚を特に罰し、実世界の整列を評価するMMHal-Benchを開発。
提案手法
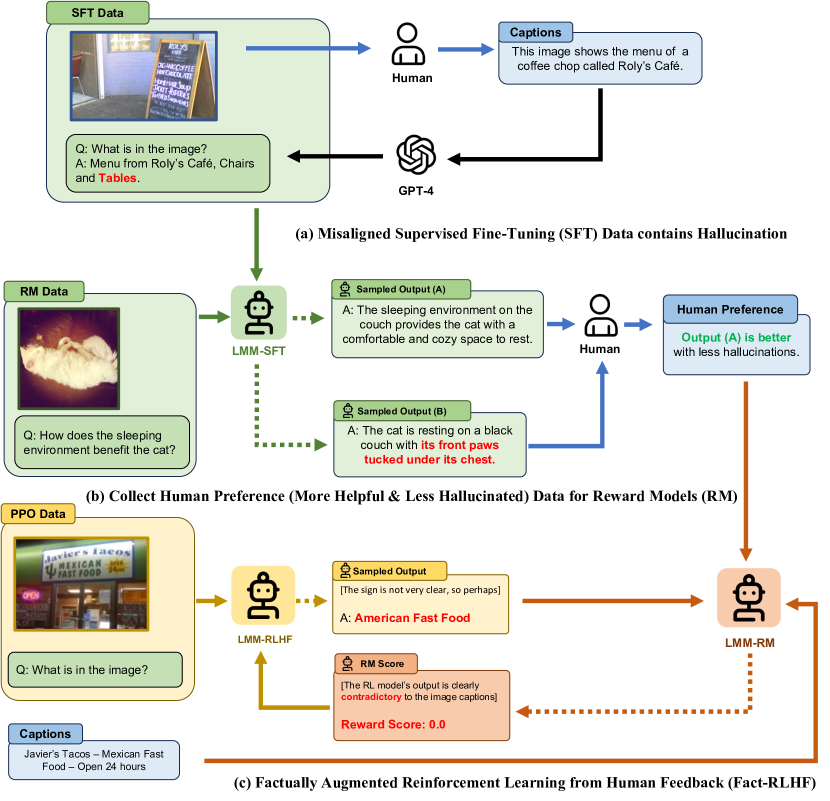
- LMMsに対して三段階のパイプラインでRLHFを適用する:多模態の教師あり微調整、多模態好みモデル、報酬モデルを用いた強化学習。
- Fact-RLHFを導入し、報酬モデルが訓練と推論時に追加の事実情報(画像キャプション、A-OKVQA推論、正解オプション)を使用して報酎ハックを抑制。
- 象徴的報酬(正解オプション)と長さペナルティを組み込み、冗長で幻覚を生みやすい出力を抑制。
- VQA-v2、A-OKVQA、Flickr30kをより構造化された高品質なビジョン指示チューニングデータセットへ変換して訓練データを拡張。
- LoRAベースの微調整でモデルをスケールし、PPOとKLペナルティを用いて更新を安定化。
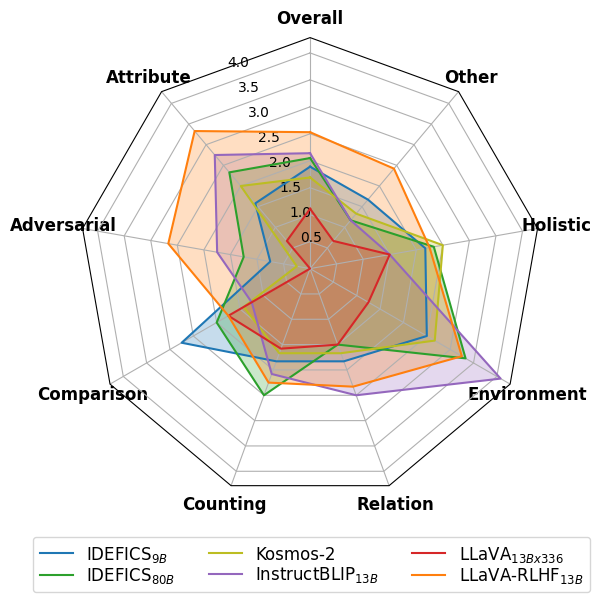
実験結果
リサーチクエスチョン
- RQ1RLHFをどのように効果的に適用して視覚的な実地真実と整列させる大規模多模態モデルを整列させることができるか。
- RQ2報酬モデルに事実情報を組み込むことで多模態幻覚と報酬ハッキングを減らせるか。
- RQ3高品質な視覚指示チューニングデータがLMMの能力と整列に与える影響は何か。
- RQ4 MMHal-Benchを用いてLMM出力の幻覚をどう測定・ベンチマークするか。
- RQ5Fact-RLHFは能力ベンチマークと整列ベンチマークの両方で標準のRLHFよりどの程度改善するか。
主な発見
- Fact-RLHFは人間の好みベンチマークで整列を改善し、標準のRLHFと比較して幻覚を減少させる。
- 高品質な視覚指示チューニングデータは、特に大規模モデルでMMBenchやPOPEなどの能力ベンチマークを著しく向上させる。
- RLHFは人間適合性ベンチマーク(MMHal-Bench、LLaVA-Bench)を向上させるが、小規模スケールでは能力ベンチマークに対して混合効果を示すことがある。
- MMHal-BenchはLMMが非実地根拠の質問で幻覚を起こしやすいことを示し、Fact-RLHFはそのような誤りを減らす。
- LLaVA-RLHFはLLaVA-Benchで94%、MMHal-Benchで60%の改善を達成し、基準値に対してMMBenchやPOPEで競争力のある結果を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。