[論文レビュー] AlphaBlock: Embodied Finetuning for Vision-Language Reasoning in Robot Manipulation
AlphaBlockはAlphaBlockデータセットとCogLoopを導入。視覚アダプタとQ-formerを用いたLLMと組み合わせ、 manipulationタスクの高レベルサブタスク計画を生成・更新するクローズドループの視覚-言語ロボット計画フレームワーク。従来手法より高い成功率を達成。
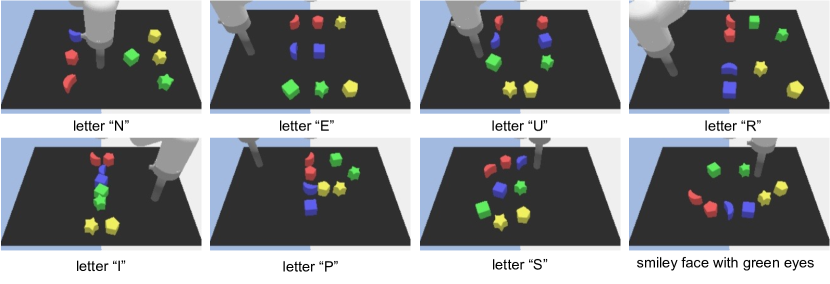
We propose a novel framework for learning high-level cognitive capabilities in robot manipulation tasks, such as making a smiley face using building blocks. These tasks often involve complex multi-step reasoning, presenting significant challenges due to the limited paired data connecting human instructions (e.g., making a smiley face) and robot actions (e.g., end-effector movement). Existing approaches relieve this challenge by adopting an open-loop paradigm decomposing high-level instructions into simple sub-task plans, and executing them step-by-step using low-level control models. However, these approaches are short of instant observations in multi-step reasoning, leading to sub-optimal results. To address this issue, we propose to automatically collect a cognitive robot dataset by Large Language Models (LLMs). The resulting dataset AlphaBlock consists of 35 comprehensive high-level tasks of multi-step text plans and paired observation sequences. To enable efficient data acquisition, we employ elaborated multi-round prompt designs that effectively reduce the burden of extensive human involvement. We further propose a closed-loop multi-modal embodied planning model that autoregressively generates plans by taking image observations as input. To facilitate effective learning, we leverage MiniGPT-4 with a frozen visual encoder and LLM, and finetune additional vision adapter and Q-former to enable fine-grained spatial perception for manipulation tasks. We conduct experiments to verify the superiority over existing open and closed-loop methods, and achieve a significant increase in success rate by 21.4% and 14.5% over ChatGPT and GPT-4 based robot tasks. Real-world demos are shown in https://www.youtube.com/watch?v=ayAzID1_qQk .
研究の動機と目的
- 言語指令に guided された多段推論を通じてロボット操作の高レベル認知能力の学習を動機付ける。
- LLMsと実行モデルで自動的に認知ロボットデータセットを生成しデータ収集の負担を軽減する。
- 視覚特徴と言語を融合してサブタスク計画を生成する多モーダル計画モデルを開発する。
- frozen LLMと視覚エンコーダを用い、軽量アダプタでロボティクスタスクのエンドツーエンド訓練を可能にする。
提案手法
- マルチラウンドプロンプトでGPT-4を用いて高レベルタスク・サブタスク計画・観察-行動列を生成することでAlphaBlockデータセットを収集する。実行モデルとしてLAVAを用いリアルタイム計画データを作成する。
- CogLoopを提案:視覚特徴を凍結した言語デコーダー(Vicuna via LLaMA)と整合させるデコーダーアーキテクチャ。視覚アダプタとVision Tokenizer(Q-former + プロジェクター)を用いて細粒度空間認識を実現。
- CogLoopを訓練して自己回帰的サブタスク計画をクロスエントロピー損失で生成し、LLMと視覚エンコーダを凍結したままアダプタとQ-formerのみを必要に応じてチューニングする。
- データ品質を保証しデータ収集時の人手を削減するため、バックトレース風プロンプティングと自己検証戦略を用いる。
- CogLoopをオープンループおよびクローズドループのベースラインと比較評価し、LAVAベースのシミュレーションコントローラで検証、また手順、再計画頻度、モダリティ構成のアブレーションを実施する。
![Figure 1: Planner model paradigms. (a) Open-loop models (SayCan-style [ 16 ] ) conduct planning and control separately. (b) Closed-loop models update plans with observation in language (Text2Motion-style [ 24 ] ). (c) We infuse more fine-grained visual observation into LLM to update planning.](https://ar5iv.labs.arxiv.org/html/2305.18898/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1AlphaBlockデータは既存のオープン/クローズドループ手法を超えた高レベル認知計画をロボット操作に適用できるか。
- RQ2閉ループの視覚-言語計画アプローチはリアルタイムでサブタスク計画を更新する際、言語のみの観察より優れているか。
- RQ3視覚アダプタとQ-formerベースのモダリティ整合が計画性能と空間推論に与える影響は。
- RQ4ロボットの有効な認知のための計画/更新頻度と計算コストのトレードオフは何か。
主な発見
| Example Model Type | Open/Closed Loop | Re-Implemented Plan Model | Success Rate (%) |
|---|---|---|---|
| SayCan [16] , open | ChatGPT | 8.1 | |
| Grounded Decoding [14] | GPT-4 | 9.0 | |
| Text2Motion [24] closed w/ language | ChatGPT | 2.1 | |
| ChatGPT for Robotics [38] | GPT-4 | 16.4 | |
| Ours (CogLoop) closed w/ vision | Embodied robot model | 23.5 |
- 視覚ベースのクローズドループ計画を含むCogLoopは成功率23.5%に達し、ChatGPT(16.4%)やLLMによる言語観察のみのGPT-4を上回る。
- 視覚情報を用いたプラン更新を行う場合、AlphaBlockはChatGPTより+21.4%、GPT-4より+7.1%の大幅な改善を実現。
- 視覚アダプタとVision Q-formerの微調整は実績を顕著に改善し、両方の要素を調整した場合が最良の結果となる。
- 総ステップ数を増やすと収束付近の約150ステップで成功率が向上し、再計画を頻繁化(10ステップごと)すると成功率は上がるが時間コストが増大する。実務的には10ステップごとの再計画がバランスが取れている。
- Franka EmikaアームとKinectセンサーでの実世界展開は、シミュレーションから実物環境への移行を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。