[論文レビュー] An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
本研究は、継続的な指示調整中の大規模言語モデル(LLMs)における破局的忘却(CF)を実証的に分析し、CFがドメイン知識、推論、読解の領域で生じ、モデルのアーキテクチャと一般的な指示調整によってやや緩和されることを示す。
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge for achieving a satisfactory performance in downstream tasks. As large language models (LLMs) have demonstrated remarkable performance, it is intriguing to investigate whether CF exists during the continual instruction tuning of LLMs. This study empirically evaluates the forgetting phenomenon in LLMs' knowledge during continual instruction tuning from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments reveal that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b parameters. Surprisingly, as the model scale increases, the severity of forgetting intensifies in such a model sale range which may result from the much significant initial performance in the larger LLM. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ exhibits less forgetting and retains more knowledge. Interestingly, we also observe that LLMs can mitigate language biases, such as gender bias, during continual fine-tuning. Furthermore, our findings indicate that general instruction tuning can help alleviate the forgetting phenomenon in LLMs during subsequent fine-tuning.
研究の動機と目的
- 継続的な指示調整の間に、LLMsに蓄積された一般知識が忘れられるかを調べる。
- どの知識タイプ(ドメイン知識、推論、読解)を忘れやすいか、あるいは忘れにくいかを特定する。
- モデルのスケールとアーキテクチャが忘却にどう影響するかを検討する。
- 一般的な指示調整が忘却を緩和するかを評価する。
- 継続的なファインチューニング中のバイアスを評価し、それらが緩和されるか増幅されるかを検討する。
提案手法
- 継続的な指示調整を模擬するための一連の生成タスク(Simp, Emdg, InqQG, Exp, HGen)を定義する。
- 複数の知識タスクにわたるFLOSS評価を用いる: ドメイン知識(MMLU)、推論(BoolQ, PIQA, Hellaswag など)、読解(RACE)、およびバイアス(CrowSPairs)。
- 忘却を FG = evaluation sets の平均で測定する(R_o - R_m)/ R_o、ここで R_o は初期の性能、R_m は m タスク後の性能。
- アーキテクチャの影響を評価するために、デコーダーのみの BLOOMZ とエンコーダ-デコーダの mT0 を比較する。
- 一般的な指示調整が忘却に及ぼす影響を調べるために LLAMA と ALPACA を取り入れる。
- BLOOMZ のスケールを 1.1B, 1.7B, 3B, 7.1B で訓練し、mT0-1.2B/3.7B および LLAMA-7B/ALPACA-7B と比較する。
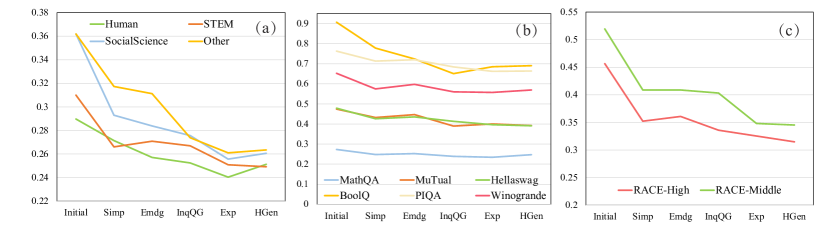
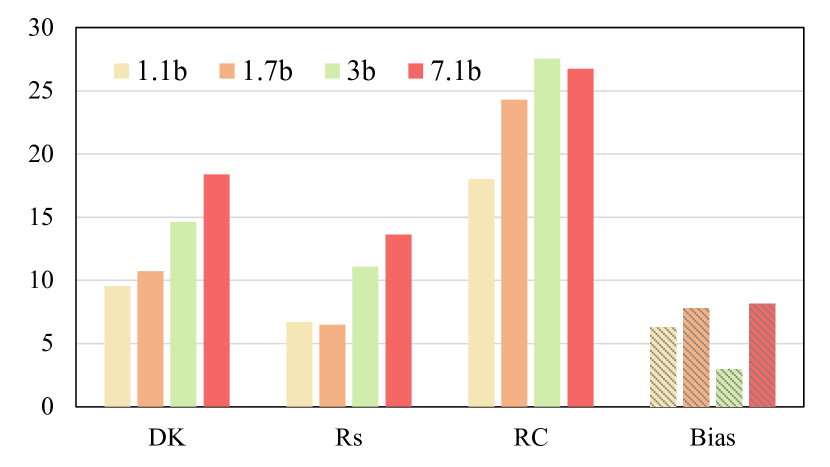
実験結果
リサーチクエスチョン
- RQ1継続的な指示調整中に、生成型LLMで破局的忘却は発生するのか。
- RQ2一般的な知識のどのタイプ(ドメイン知識、推論、読解)が忘却の影響を最も受けるのか。
- RQ3モデルのスケールは忘却の深刻さにどう影響するか。
- RQ4アーキテクチャ(デコーダーのみ vs エンコーダ-デコーダ)は忘却にどう影響するか。
- RQ5一般的な指示調整は追加のファインチューニング中の忘却を緩和できるか。
- RQ6継続的なファインチューニング中のバイアスはどのように影響されるか。
主な発見
- CF exists across tested models and tasks during continual instruction tuning.
- Forgetting generally increases with model scale, especially in domain knowledge and reading comprehension.
- Decoder-only BLOOMZ tends to forget less than encoder-decoder mT0 at comparable scales."
- General instruction tuning (ALPACA, LLAMA+ALPACA) can help mitigate forgetting in subsequent fine-tuning, depending on initial performance.
- Bias measures show mitigation of some biases during continual tuning, indicating a bias-reduction effect.
- Reading comprehension shows the strongest forgetting among the evaluated domains (e.g., large FG values at higher scales).
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。