[論文レビュー] Analyzing Chain-of-Thought Prompting in Large Language Models via Gradient-based Feature Attributions
本論文は勾配ベースの顕著性手法を用いて、チェーン・オブ・思考 prompting がオープンソース LLMs の入力トークン重要度に与える影響を分析する。CoT は顕著性の大きさを高めるわけではないが、質問の置換や出力のランダム性に対する頑健性を向上させる。
Chain-of-thought (CoT) prompting has been shown to empirically improve the accuracy of large language models (LLMs) on various question answering tasks. While understanding why CoT prompting is effective is crucial to ensuring that this phenomenon is a consequence of desired model behavior, little work has addressed this; nonetheless, such an understanding is a critical prerequisite for responsible model deployment. We address this question by leveraging gradient-based feature attribution methods which produce saliency scores that capture the influence of input tokens on model output. Specifically, we probe several open-source LLMs to investigate whether CoT prompting affects the relative importances they assign to particular input tokens. Our results indicate that while CoT prompting does not increase the magnitude of saliency scores attributed to semantically relevant tokens in the prompt compared to standard few-shot prompting, it increases the robustness of saliency scores to question perturbations and variations in model output.
研究の動機と目的
- Chain-of-Thought prompting がモデル挙動に与える良し悪しを理解することで責任ある展開を促進する。
- CoT prompting がトークンレベルの重要度とモデルの頑健性を Few-shot QA タスクにおいて変化させるかを調査する。
- 1–6B パラメータのモデル間および複数の QA データセットにわたって効果が一貫して現れるかを評価する。
提案手法
- プロンプト-質問入力に対して通常の勾配ベースおよびコントラスト勾配ベースの顕著性法(gradient x input および L1 ノルム)を適用する。
- 標準 prompting と CoT prompting を、GPT-J (6B)、GPT-Neo (2.7B)、GPT-2 XL (1.5B) の4データセットで比較する。
- 質問に意味的に関連するトークンの顕著性を評価する。
- 質問の言い換えとモデル出力の確率的変動に対する頑健性を、繰り返し実行で検証する。
- GSM8K、CoinFlip、CSQA、SST から 50 問題のサブセットを eight-shot prompts で使用する。
- 顕著性の大きさと条件ごとのばらつきを報告する。
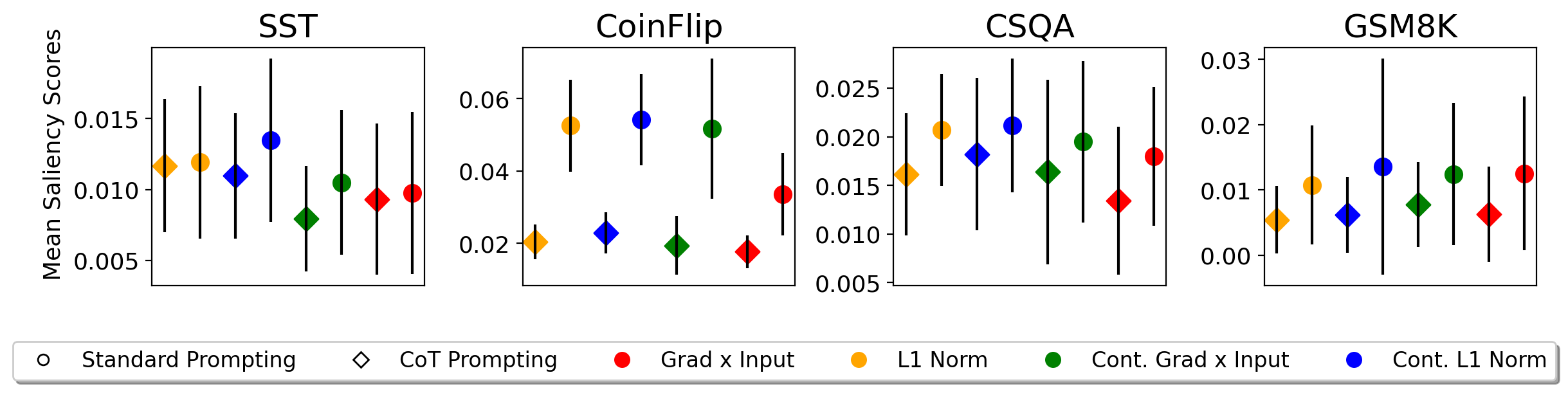
実験結果
リサーチクエスチョン
- RQ1CoT prompting は意味的に関連する質問トークンの顕著性の大きさを高めるのか?
- RQ2CoT prompting は質問の言い換えに対するモデルの顕著性応答をより頑健にするのか?
- RQ3CoT prompting はモデル出力の確率的変動に対して顕著性スコアを安定化させるのか?
- RQ4CoT prompting の顕著性への効果は、複数のオープンソース LLM および複数の QA データセットに一般化するのか?
主な発見
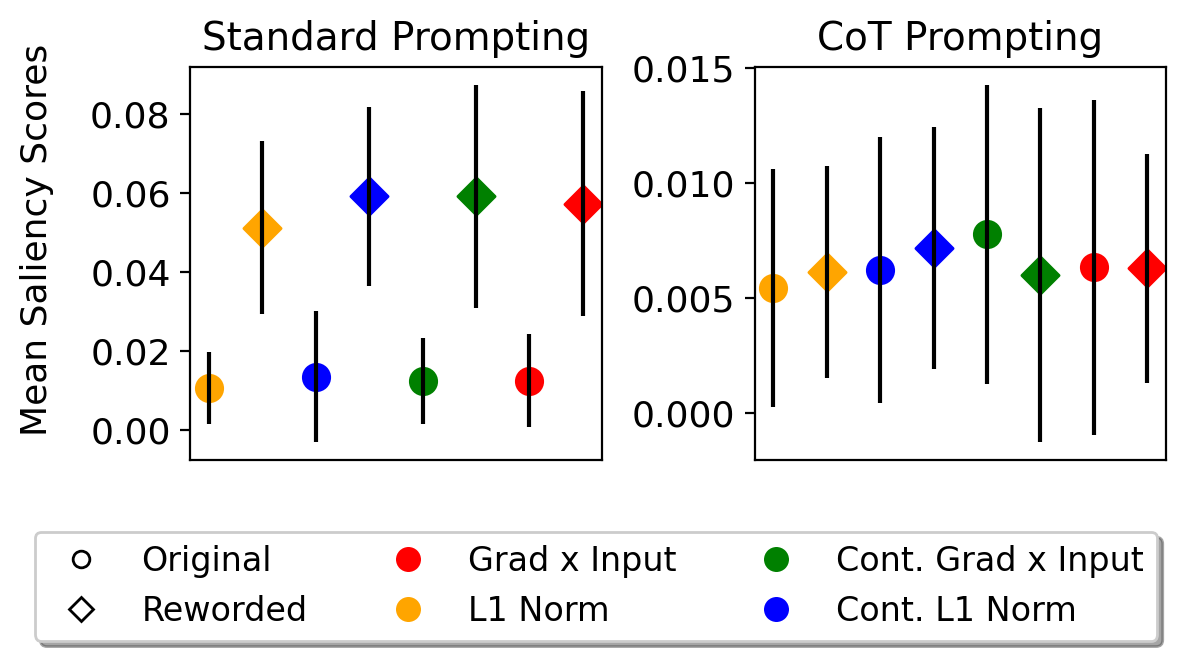
- CoT prompting は、データセットや手法を問わず、関連入力トークンの顕著性の大きさを増加させない。
- CoT prompting は、関連トークンの顕著性スコアを質問の変動や言い換えに対してより頑健にする。
- CoT prompting は、異なるモデル出力間で関連トークンの勾配をより安定させ、分散を低下させる。
- SST を除く例外なく、6B パラメータ規模で CoT prompting による正確性の向上は見られず、SST でのみ正確性が増加する。
- 異なる勾配ベースのアトリビューション手法は大きく異なる値を生じさせ、方法論的感度を示す。
- 本研究は、解釈可能性ツールが最終的な説明を超えた CoT prompting の機構的側面を照らしうることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。