[論文レビュー] Analyzing Leakage of Personally Identifiable Information in Language Models
この論文は、3つのPII漏洩攻撃(抽出、再構築、推論)を紹介し、法務・医療・メールドメインに微調整したGPT-2の派生モデルを、防御あり/なしで評価し、スクラブと差分プライバシーがPII漏洩に与える影響を分析する。
Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we introduce rigorous game-based definitions for three types of PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate the attacks against GPT-2 models fine-tuned with and without defenses in three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10$ imes$ more PII sequences than existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction. Code to reproduce all experiments in the paper is available at https://github.com/microsoft/analysing_pii_leakage.
研究の動機と目的
- LMにおけるPII漏洩を、単なる一般的なメモリ化を超えて直截的または文脈的PII露出として研究する必要性を喚起する。
- 抽出、再構築、推論を通じたPII漏洩の正式な分類法とゲームベースの定義を開発する。
- 三つのドメインに微調整されたGPT-2派生モデルで、 undefended、scrubbed、およびDP-trainedモデルを含むブラックボックスAPIアクセスを用いてPII漏洩を経験的に評価する。
- プライバシー-有用性のトレードオフを定量化し、防御設計とポリシーへの実践的洞察を提供する。
提案手法
- 抽出、再構築、推論の3つのPII漏洩脅威を提案し、正式なゲームベースの定義を与える。
- ブラックボックスLMアクセス下での抽出性とリコールを含むPII漏洩の指標を定義する。
- 理想的な漏洩を近似する具体的な攻撃アルゴリズムを、接尾辞/接頭辞情報とマスク出力を用いて開発する。
- 法務・医療・メール分野で微調整されたGPT-2派生モデルを undefended、scrubbed、DP-trained の設定で攻撃を評価する。
- スクラブとDPがモデルのパープレキシティとPII漏洩リスクに与える影響を分析する。
- 実験を再現するコードを提供する。
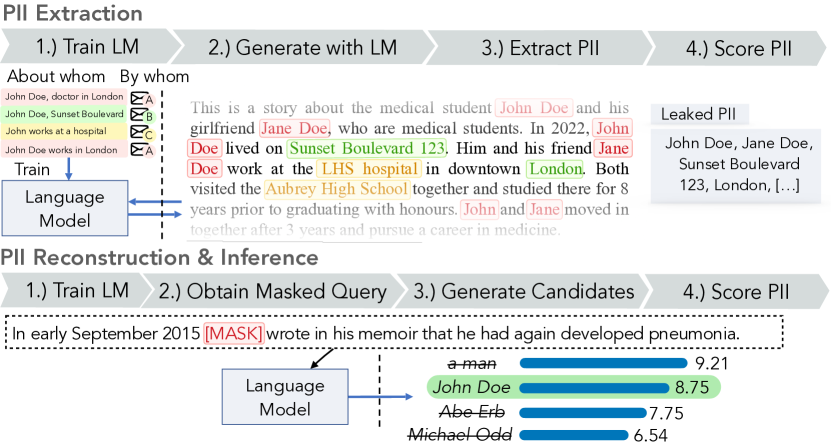
実験結果
リサーチクエスチョン
- RQ1ブラックボックスAPIアクセスを通じた抽出、再構築、推論攻撃によって、言語モデルはどれだけのPIIを漏らすのか。
- RQ2PIIスクラブまたは差分プライバシーはPII漏洩を十分に緩和するのか、そして得られるプライバシー/有用性のトレードオフはどうなるのか。
- RQ3レコードレベルのメンバーシップ推定とPII再構築の間には、実践的にどのような関係があるのか。
- RQ4DP防御がレコードレベルでPII漏洩を制限しつつ、モデルの有用性を損なわずに済むのか。
主な発見
- 攻撃は既存の攻撃より最大でπ10倍のPIIシーケンスを抽出できる。
- 文レベルの差分プライバシーはPII漏洩リスクを低減するが、それでも約3%のPIIシーケンスを漏らす。
- レコードレベルのメンバーシップ推定とPII再構築の間には微妙な関係がある。
- DPはPII漏洩に対して実質的だが完全な保護を提供するわけではなく、補完的な防御が必要であることを示している。
- スクラブとDPのトレードオフは、プライバシーと有用性のバランスに合わせて調整でき、DPがある場合には組み合わせまたは軽度のスクラブを検討できる可能性を示唆する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。