[論文レビュー] Applications and Advances of Artificial Intelligence in Music Generation:A Review
この論文はAIベースの音楽生成を系統的にレビューし、象徴的、オーディオ、ハイブリッドのアプローチ、主要なモデルとデータセット、評価手法、分野横断的な応用を詳述し、課題と今後の方向性を論じる。
In recent years, artificial intelligence (AI) has made significant progress in the field of music generation, driving innovation in music creation and applications. This paper provides a systematic review of the latest research advancements in AI music generation, covering key technologies, models, datasets, evaluation methods, and their practical applications across various fields. The main contributions of this review include: (1) presenting a comprehensive summary framework that systematically categorizes and compares different technological approaches, including symbolic generation, audio generation, and hybrid models, helping readers better understand the full spectrum of technologies in the field; (2) offering an extensive survey of current literature, covering emerging topics such as multimodal datasets and emotion expression evaluation, providing a broad reference for related research; (3) conducting a detailed analysis of the practical impact of AI music generation in various application domains, particularly in real-time interaction and interdisciplinary applications, offering new perspectives and insights; (4) summarizing the existing challenges and limitations of music quality evaluation methods and proposing potential future research directions, aiming to promote the standardization and broader adoption of evaluation techniques. Through these innovative summaries and analyses, this paper serves as a comprehensive reference tool for researchers and practitioners in AI music generation, while also outlining future directions for the field.
研究の動機と目的
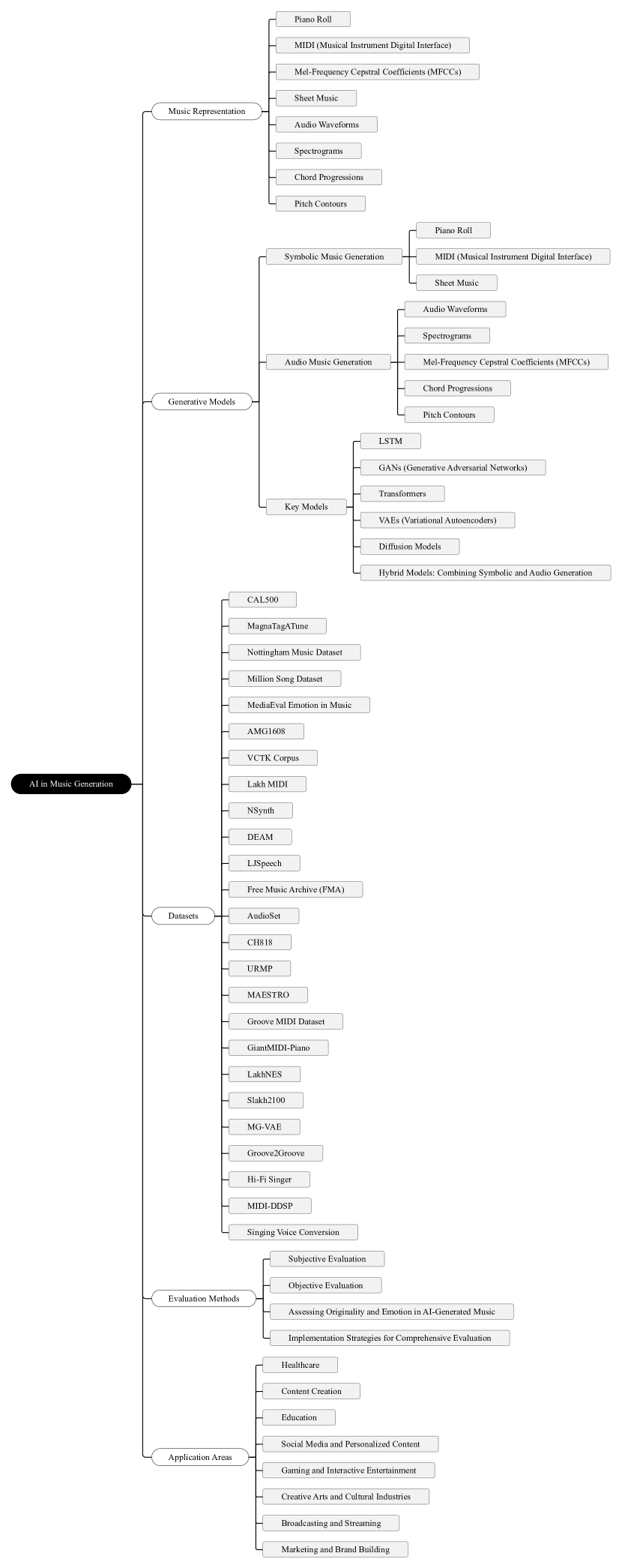
- 象徴的、オーディオ、およびハイブリッドAI音楽生成アプローチを分類・比較するための包括的な枠組みを提供する。
- AI音楽生成におけるモデル、データセット、評価手法に関する現在の文献を調査する。
- さまざまなドメインでのAI生成音楽の実践的な応用とリアルタイム対話を分析する。
- 音楽品質評価の課題を特定し、標準化と今後の研究の方向性を提案する。
提案手法
- 象徴的、オーディオ、ハイブリッド生成手法を分類する体系的な枠組みを開発する。
- 代表的なモデル(GAN、Transformer、VAE、拡散)とそれらの能力・限界を調査する。
- モデル訓練における一般的に使用されるデータセットとそれらの役割を要約する。
- 評価手法と音楽品質評価における課題について論じる。
- 象徴-オーディオ付きのハイブリッドフレームワークや連鎖拡散/階層的アプローチを探る。
- 標準化とより広い適用のための将来の研究方向を概説する。
実験結果
リサーチクエスチョン
- RQ1音楽生成に用いられる主なAIアプローチ(象徴的、オーディオ、ハイブリッド)は何で、それぞれの長所と短所は何か?
- RQ2どのデータセットと評価手法が普及しており、それらが生成音楽の品質にどのように影響するか?
- RQ3AI生成音楽の実用的な応用分野とそれらの要件は何か?
- RQ4音楽品質、整合性、ティンバー制御の主要な課題は何か、そしてそれらに対処する未来の方向性は?
主な発見
- AI音楽生成は、記号的(MIDI/ピアノロール)からオーディオ(波形、スペクトログラム)へ、そしてますますハイブリッドモデルへと発展している。
- Transformers、GANs、拡散モデルは、構造化された多様で高品質な音楽を生成するうえで中心的であり、拡散モデルは高忠実度オーディオを可能にしている。
- ハイブリッドフレームワークは、象徴的構造と豊かなオーディオティンバーを組み合わせ、結束性と表現力を向上させる。
- 大規模データセットと自己教師付きまたは階層的学習はモデルの頑健性を高めるが、計算と評価の課題を生む。
- 音楽品質の評価は依然として大きな課題であり、標準化された方法とより広範な評価フレームワークの提案を促している。
- リアルタイム対話、教育、医療、コンテンツ制作など、幅広い応用が存在する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。