[論文レビュー] ARAGOG: Advanced RAG Output Grading
論文は retrieval-augmented generation (RAG) 技術を複数比較し、retrieval precision と answer similarity を評価している。HyDE と LLM-based reranking が retrieval quality を向上させ、Sentence Window retrieval が最高の retrieval precision を示す。一方、いくつかの技術は Naive RAG を上回らない。
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA) techniques against their predecessors, with a gap in extensive experimental comparisons. This study begins to address this gap by assessing various RAG methods' impacts on retrieval precision and answer similarity. We found that Hypothetical Document Embedding (HyDE) and LLM reranking significantly enhance retrieval precision. However, Maximal Marginal Relevance (MMR) and Cohere rerank did not exhibit notable advantages over a baseline Naive RAG system, and Multi-query approaches underperformed. Sentence Window Retrieval emerged as the most effective for retrieval precision, despite its variable performance on answer similarity. The study confirms the potential of the Document Summary Index as a competent retrieval approach. All resources related to this research are publicly accessible for further investigation through our GitHub repository ARAGOG (https://github.com/predlico/ARAGOG). We welcome the community to further this exploratory study in RAG systems.
研究の動機と目的
- 高度な RAG 技術のスペクトラムが retrieval precision と answer similarity にどのような影響を与えるかを評価する。
- RAG パイプライン全体で、retrieval と generation コンポーネントのどの組み合わせが最も高い性能を発揮するかを特定する。
- retrieval 品質、待機時間(遅延)、コストのトレードオフについて実用的な指針を提供する。
- コミュニティによる再現と拡張を可能にするため、実験的パイプラインを公開する。
提案手法
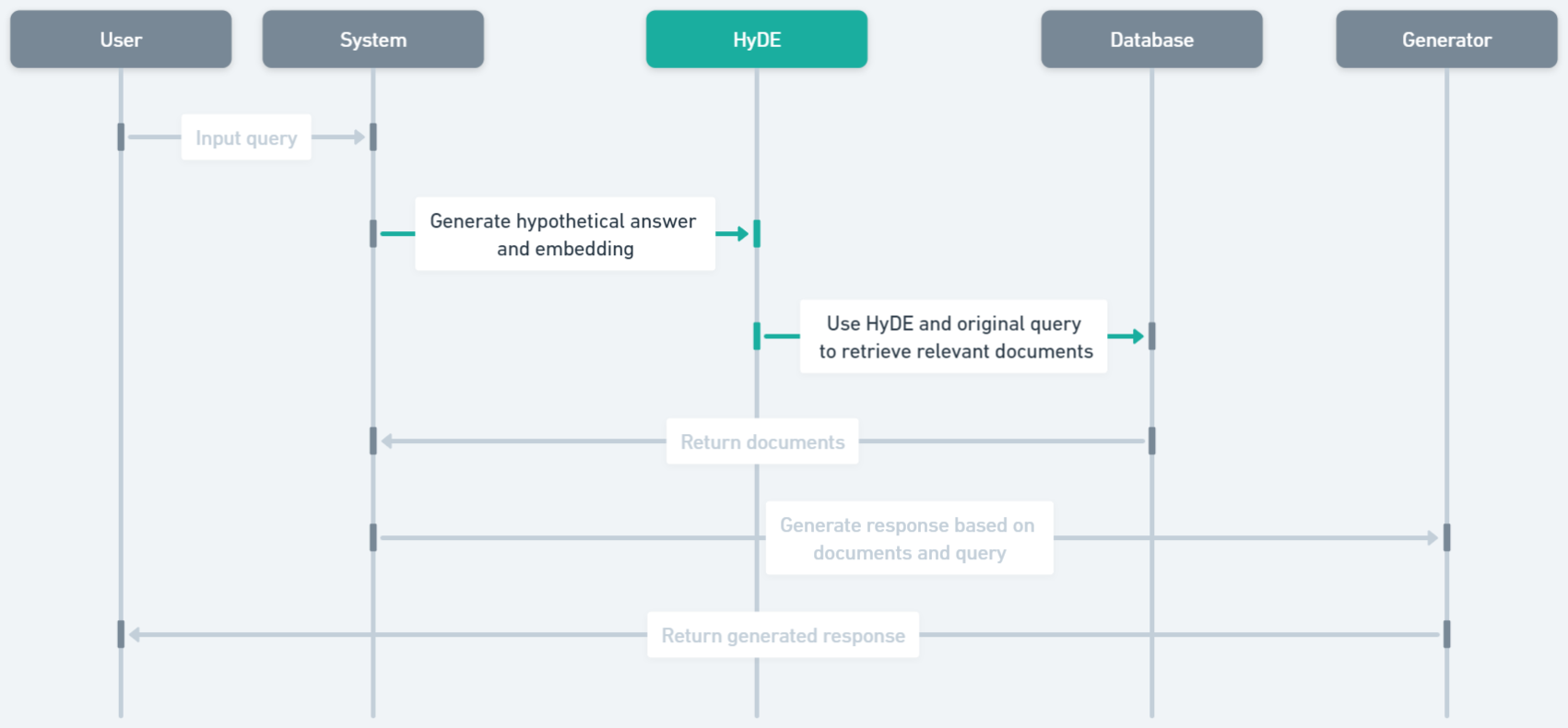
- Sentence-window retrieval、Document Summary Index、HyDE、Multi-query、MMR、Cohere rerank、および LLM rerank を含む幅広い RAG 技術を評価する。
- 各手法のニーズを反映するため、512-token トークンで 50-token overlap、3-sentence windows、3072-token summaries などの異なるチャンク化戦略を用いてベクターデータベースを構築する。
- 生成には GPT-3.5-turbo を用い、評価には Tonic Validate 指標を用いた LLM を用いる。
- LLM の変動性を緩和するため、各技術ごとに 10 回の実行で Retrieval Precision および Answer Similarity (0-5) を測定する。
- retrieval precision の差の統計的有意性を評価するために ANOVA と Tukey’s HSD を適用する。
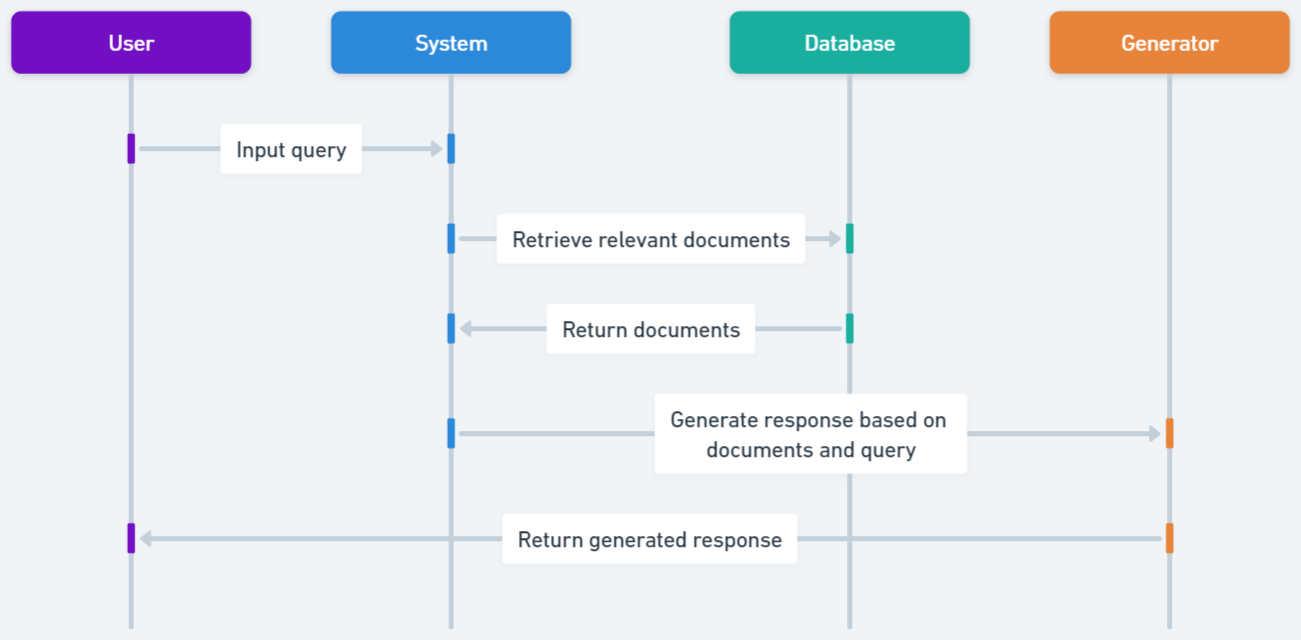
実験結果
リサーチクエスチョン
- RQ1Naive RAG に対してどの RAG 技術が最も retrieval precision を改善するのか?
- RQ2retrieval precision と answer similarity およびコストのトレードオフはどうなるのか?
- RQ3HyDE や reranker のような技術はデータセットやチャンクング方式を問わず一貫して基準を上回るのか?
- RQ4Sentence Window retrieval は構成に関係なく retrieval precision において一貫して優れているのか?
主な発見
- HyDE および LLM reranking は Naive RAG に比して retrieval precision を著しく改善する。
- Sentence Window Retrieval は高い retrieval precision を生み出し、しばしば従来のベクトルデータベースのベースラインを上回る。
- MMR および Cohere rerank は retrieval precision において Naive RAG と比べてほとんど改善をもたらさない。
- Multi-query アプローチは retrieval precision でベースライン Naive RAG と比較して劣る。
- Document Summary Index アプローチは最良の Classic VDB 設定と同等の性能を示すが、事前の要約作業が必要である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。