[論文レビュー] ARB: Advanced Reasoning Benchmark for Large Language Models
ARB は、数学、物理、化学、生物学、法律を跨る難易度の高い大学院レベルの推論ベンチマークです。ルーブリックベースの自己評価アプローチを導入し、現状のLLMは高度な定量タスクで依然として性能不足であることを示します。
Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.
研究の動機と目的
- ARB を新しいベンチマークとして紹介し、複数分野にまたがる専門的・大学院レベルの推論を評価する。
- 専門/大学院資料から出典された数学、物理学、生物学、化学、法の多様な問題を提供する。
- 中間的推論過程の自己評価を可能にするルーブリックベースの評価を提案・検証する。
- モデルの性能(GPT-4、GPT-3.5、Claude)を示し、エラータイプと評価の信頼性を分析する。
提案手法
- ベンチマークは3種類の問題形式:多肢選択式、短答式、オープンレスの構成で、短答/オープンエンド問題の比率を高く設定する。
- 問題は標準化試験、問題集、大学院試験、バーレー/法学資料から出典され、大学院レベルの難易度を保証する。
- 自動解析と採点手順は多肢選択と数値回答に対して用いられ、記号回答には SymPy ベースの解析を用いる。
- モモデルベースのルーブリック評価アプローチを導入し、GPT-4 が参照解からルーブリックを生成し、それを用いて解答を採点する。
- ルーブリックベースのスコアと人間の評価を比較するため、記号集合の手動評価を行い、カバレッジとクレジット割り当てを評価する。
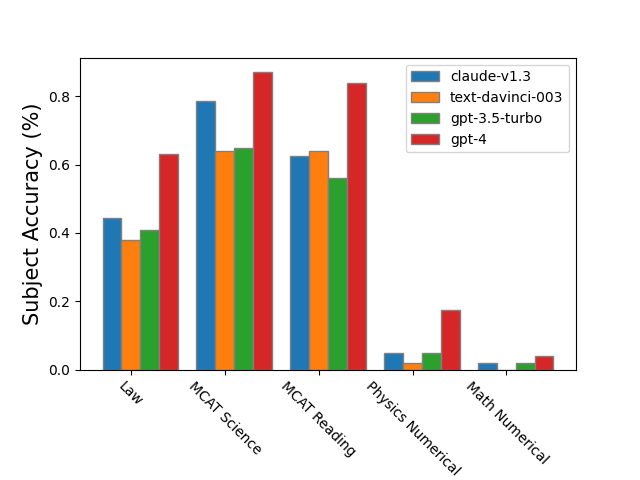
実験結果
リサーチクエスチョン
- RQ1現在のLLM(例:GPT-4、GPT-3.5、Claude)は、分野横断のARBの高度推論タスクでどの程度性能を示すか?
- RQ2ルーブリック生成・モデルベース評価は、記号的・証明類似問題に対して人間の採点を信頼性高く近似できるか?
- RQ3高度な数学・物理問題においてLLMはどのような誤りを犯し、問題タイプによってこれらの誤りはどう異なるか?
- RQ4ルーブリックによる自己評価は人間判断と相関し、自動採点の頑健性を向上させるか?
主な発見
- 現行モデルはARBの多くの高度な定量タスクで専門家レベルを大きく下回る。
- GPT-4 は複雑な式を簡略化できるが、長文contextの算術や記号操作には依然苦戦。
- 記号的・証明風の問題は、モデル全体で顕著な失敗率を示し、カテゴリ別に明示的な表形式の割合が報告されている。
- GPT-4 によるルーブリック評価は、人間の採点と中程度の高い相関を示す(例:物理記号、数学記号、証明風の問題)。
- GPT-4生成のルーブリックは重要な解決手順を適切にカバーするが、得点の割り当てを誤る場合がある。ルーブリックベースの採点は評価労力を減らし、手動評価と整合する。
- ルーブリックを用いたモデルベース評価は正誤の自動代理指標として有望だが、人間の採点の完全な代替にはならない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。