[論文レビュー] ARBEx: Attentive Feature Extraction with Reliability Balancing for Robust Facial Expression Learning
ARBExは、Window-Based Cross-Attention Vision Transformerに基づく注意機構付き特徴抽出フレームワークを導入し、学習可能なアンカーとマルチヘッド自己注意を用いてバイアス、不確実性、および表情分類のデータ分布の偏りに対処し、データセット全体で最先端の結果を達成します。
In this paper, we introduce a framework ARBEx, a novel attentive feature extraction framework driven by Vision Transformer with reliability balancing to cope against poor class distributions, bias, and uncertainty in the facial expression learning (FEL) task. We reinforce several data pre-processing and refinement methods along with a window-based cross-attention ViT to squeeze the best of the data. We also employ learnable anchor points in the embedding space with label distributions and multi-head self-attention mechanism to optimize performance against weak predictions with reliability balancing, which is a strategy that leverages anchor points, attention scores, and confidence values to enhance the resilience of label predictions. To ensure correct label classification and improve the models' discriminative power, we introduce anchor loss, which encourages large margins between anchor points. Additionally, the multi-head self-attention mechanism, which is also trainable, plays an integral role in identifying accurate labels. This approach provides critical elements for improving the reliability of predictions and has a substantial positive effect on final prediction capabilities. Our adaptive model can be integrated with any deep neural network to forestall challenges in various recognition tasks. Our strategy outperforms current state-of-the-art methodologies, according to extensive experiments conducted in a variety of contexts.
研究の動機と目的
- FELにおけるバイアス、不確実性、およびクラス分布の問題に対処する。
- クロスアテンションとマルチスケール特徴を活用した堅牢な特徴抽出パイプラインをVision Transformerで開発する。
- ラベル分布の安定化を図るため、アンカー点と注意補正を用いた信頼性バランシングを導入する。
- 過学習を抑制するため、重いデータ拡張とデータ精製を伴うトレーニングパイプラインを提供する。
提案手法
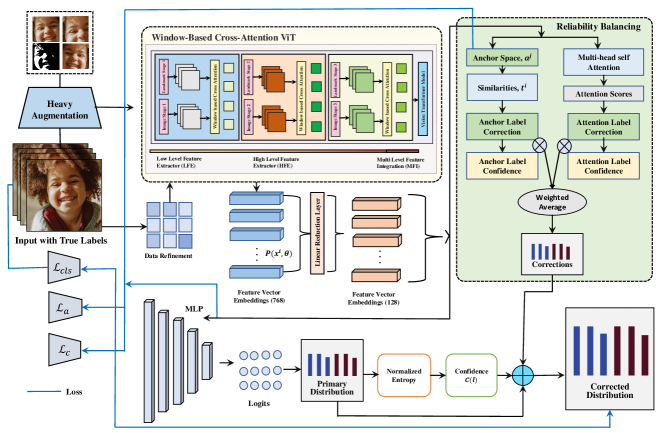
- 画像バックボーンと顔のランドマークからのマルチレベル特徴を融合し、768次元の埋め込みへ変換したWindow-Based Cross-Attention ViT (W-MCSA)を用い、分類のために128次元の線形還元を行う。
- 埋め込みeからの主ラベル分布l = softmax(f(e))を計算し、正規化エントロピーで信頼度を推定する。
- 埋め込み空間の学習可能なアンカーa^{i,j}とマルチヘッド自己注意を導入し、アンカーを用いた補正t_gと注意補正t_aを導出する。
- 補正を加重スキームで結合し、信頼度ベースの重みで調整された最終ラベル分布L_finalを得る。
- 損失は複合損失として、クラス分布損失、アンカー損失(アンカー間のマージン最大化)、センタ損失(埋め込みをクラスアンカーに引き寄せる)を用いる。
- 表現の多様性とバランスの取れたトレーニングバッチを確保するため、重いデータ拡張とデータ精製戦略を採用する。
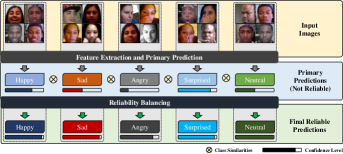
実験結果
リサーチクエスチョン
- RQ1アンカーと注意による信頼性バランシングは、 biased/unbalanced なラベル分布下でFELの性能を改善できるか。
- RQ2Window-based cross-attention ViTはマルチスケール特徴とランドマークを効果的に融合して堅牢な表情認識を実現できるか。
- RQ3アンカーベースの補正と注意補正はラベルの信頼性と最終予測の信頼度にどのような影響を与えるか。
- RQ4重いデータ拡張とデータ精製はFELベンチマークの過学習防止にどの程度寄与するか。
主な発見
| K | Accuracy (%) |
|---|---|
| 0 | 68.92 |
| 1 | +1.82 ( ↑ ) |
| 2 | +2.03 ( ↑ ) |
| 3 | +2.11 ( ↑ ) |
| 4 | +2.19 ( ↑ ) |
| 5 | +2.24 ( ↑ ) |
| 6 | +2.26 ( ↑ ) |
| 8 | +2.29 ( ↑ ) |
| 10 | +0.51 ( ↑ ) |
- ARBExフレームワークは、多様なデータセット(Aff-Wild2, RAF-DB, JAFFE, FER関連ベンチマーク)で多くの最先端 FEL システムを超える。
- 学習可能なアンカーとマルチヘッド注意による信頼性バランシングは、ラベルノイズやバイアス下でラベル分布を安定化し予測信頼度を向上させる。
- マルチスケール特徴融合を備えた窓型クロスアテンションViTは、表情分類に適したロバストな埋め込みを生成する。
- アンカー数Kの影響を実験的に検証し、高値のKを超えると得られる利得が鈍化することから、アンカーの適切な最適点が存在する。
- アンカー損失、センター損失、クラス分布損失を組み合わせることで、埋め込みの識別性と安定性が向上する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。