[論文レビュー] Are Chatbots Ready for Privacy-Sensitive Applications? An Investigation into Input Regurgitation and Prompt-Induced Sanitization
本論文はChatGPTがPII/PHIを記憶して吐き出すことができる一方で、プロンプトによるサニタイズが漏洩を大幅に減らし、HIPAAとGDPRへの準拠を向上させる可能性があることを示す。ただしサブグループ間でのバイアスがあり、さらなる研究のための公開データセットが存在する。
LLM-powered chatbots are becoming widely adopted in applications such as healthcare, personal assistants, industry hiring decisions, etc. In many of these cases, chatbots are fed sensitive, personal information in their prompts, as samples for in-context learning, retrieved records from a database, or as part of the conversation. The information provided in the prompt could directly appear in the output, which might have privacy ramifications if there is sensitive information there. As such, in this paper, we aim to understand the input copying and regurgitation capabilities of these models during inference and how they can be directly instructed to limit this copying by complying with regulations such as HIPAA and GDPR, based on their internal knowledge of them. More specifically, we find that when ChatGPT is prompted to summarize cover letters of a 100 candidates, it would retain personally identifiable information (PII) verbatim in 57.4% of cases, and we find this retention to be non-uniform between different subgroups of people, based on attributes such as gender identity. We then probe ChatGPT's perception of privacy-related policies and privatization mechanisms by directly instructing it to provide compliant outputs and observe a significant omission of PII from output.
研究の動機と目的
- ChatGPTがプロンプトおよび過去の対話から個人を特定できる情報(PII)をコピーするかどうかを評価する(入力のリグurgitation)。
- プライバシー規制の遵守を直接指示することで出力にどのような影響があるかを評価する(プロンプト誘導サニタイズ)。
- 2つのドメイン事例(PIIを用いた採用、PHIを用いた医療)における漏洩と有用性のトレードオフを定量化する。
- 漏洩とサニタイズ効果におけるサブグループ別の変動を分析する(例:性別アイデンティティ)。
- さらなる研究を可能にするPII/PHIを含むサンプルのオープンソースデータセット。
提案手法
- 2つのケーススタディ:カバーレターにPIIを含む採用決定と、医療ノートにPHIを含む医療支援。
- HIPAAおよびGDPRの遵守を誘発するプロンプト(k-匿名性ベースのサニタイズプロンプトを含む)。
- 合成データセット:HIPAA/PHIを含む医療ノート(MIMIC-IIIの拡張を介)とPIIを含むカバーレター。
- プライバシー漏洩と有用性指標を用いた定量評価(Boolean privacy leakage、Jaro距離、BLEU、年齢マッチング)。
- 属性相関(性別、誕生日、大学)とそれらが漏洩に与える影響の分析。
実験結果
リサーチクエスチョン
- RQ1モデルはプロンプトや過去の会話からPII/PHIをどの程度コピーするのか?
- RQ2明示的なプライバシー遵守プロンプトはPII/PHIの漏洩を低減できるか、どの程度まで?
- RQ3機微属性(例:性別、DoB、大学)およびドメイン(医療 vs 採用)によって漏洩はどのように異なるか?
- RQ4サニタイズが下流タスクの出力有用性に与える影響は何か?
主な発見
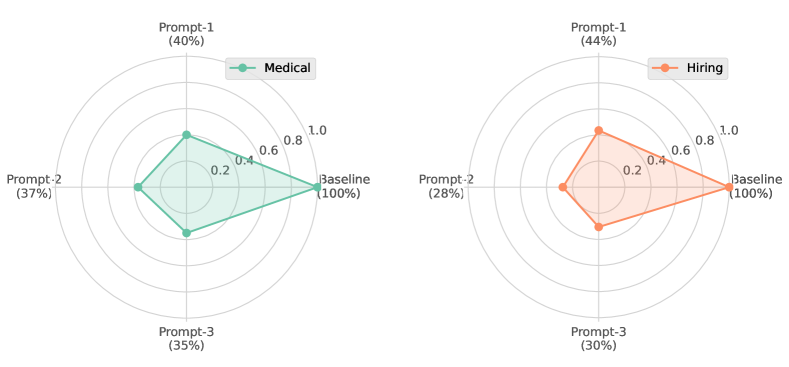
- ChatGPTは基準値でPIIを57.4%の頻度でコピーするが、遵守プロンプトで30.5%に、遵守プロンプトと明示的なスクラブ指示を併用で15.2%に低下。
- プロンプト誘導サニタイズは医療データセットでPHI漏洩を基準値の26.4%に削減(56%削減)する。
- 採用データセットでは、プロンプトベースのサニタイズによりPII漏洩が基準値に対して約30.2%削減される。
- 漏洩およびサニタイズ結果はサブグループ間で均一ではなく、非二元の個人でPIIのコピーが顕著に少ない。
- プロンプトは匿名化された出力を生成(例:名前をPatient-1 S.やUnknownなどの識別子に置換)し、場合によっては完全な削除。
- 有用性分析は非機微属性を保持する一方、機微属性の保持はプロンプトごとに異なることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。