[論文レビュー] Are Chatbots Reliable Text Annotators? Sometimes
この論文はオープンソースLLM、ChatGPT、従来の監視付き分類器を体系的に比較し、US政治ツイートにおける二値テキスト注釈タスクで監視付きモデルが一貫してLLMsを上回すことを明らかにし、ChatGPTは断続的に競合するに留まり、オープンソースモデルはOpen Scienceの明確な利点を提供しないと結論付ける。
Recent research highlights the significant potential of ChatGPT for text annotation in social science research. However, ChatGPT is a closed-source product which has major drawbacks with regards to transparency, reproducibility, cost, and data protection. Recent advances in open-source (OS) large language models (LLMs) offer an alternative without these drawbacks. Thus, it is important to evaluate the performance of OS LLMs relative to ChatGPT and standard approaches to supervised machine learning classification. We conduct a systematic comparative evaluation of the performance of a range of OS LLMs alongside ChatGPT, using both zero- and few-shot learning as well as generic and custom prompts, with results compared to supervised classification models. Using a new dataset of tweets from US news media, and focusing on simple binary text annotation tasks, we find significant variation in the performance of ChatGPT and OS models across the tasks, and that the supervised classifier using DistilBERT generally outperforms both. Given the unreliable performance of ChatGPT and the significant challenges it poses to Open Science we advise caution when using ChatGPT for substantive text annotation tasks.
研究の動機と目的
- ソーシャルサイエンス文書における二値注釈タスクに対するオープンソースLLM(OS LLM)の性能をChatGPTおよび伝統的な監督モデルと比較して評価する。
- ゼロショットおよびファew-shot学習と汎用プロンプト vs. カスタムプロンプトがモデル性能に及ぼす影響を評価する。
- 透明性、再現性、コストの観点からOpen Scienceの含意を、モデリングアプローチ間で比較する。
提案手法
- Ground truthとして米国ニュースメディアの人手注釈ツイート2,900件の新しいデータセットを使用する。
- 二つの二値分類タスクを評価する:政治的か非政治的か、 exemplar contentか非exemplar contentか。
- DistilBERT(監督付き)をOS LLMs(Beluga-13B、FLAN-T5-XXL、all-MiniLM-L6、BGE-large-en)およびChatGPT(GPT-3.5-turbo、GPT-4)と比較する。
- ゼロショット設定およびファew-shot設定、汎用プロンプトとカスタムプロンプトを組み合わせて実験する。
- 精度とF1スコアを用いて性能を測定し、注釈におけるKrippendorff信頼性がground truthを案内する。
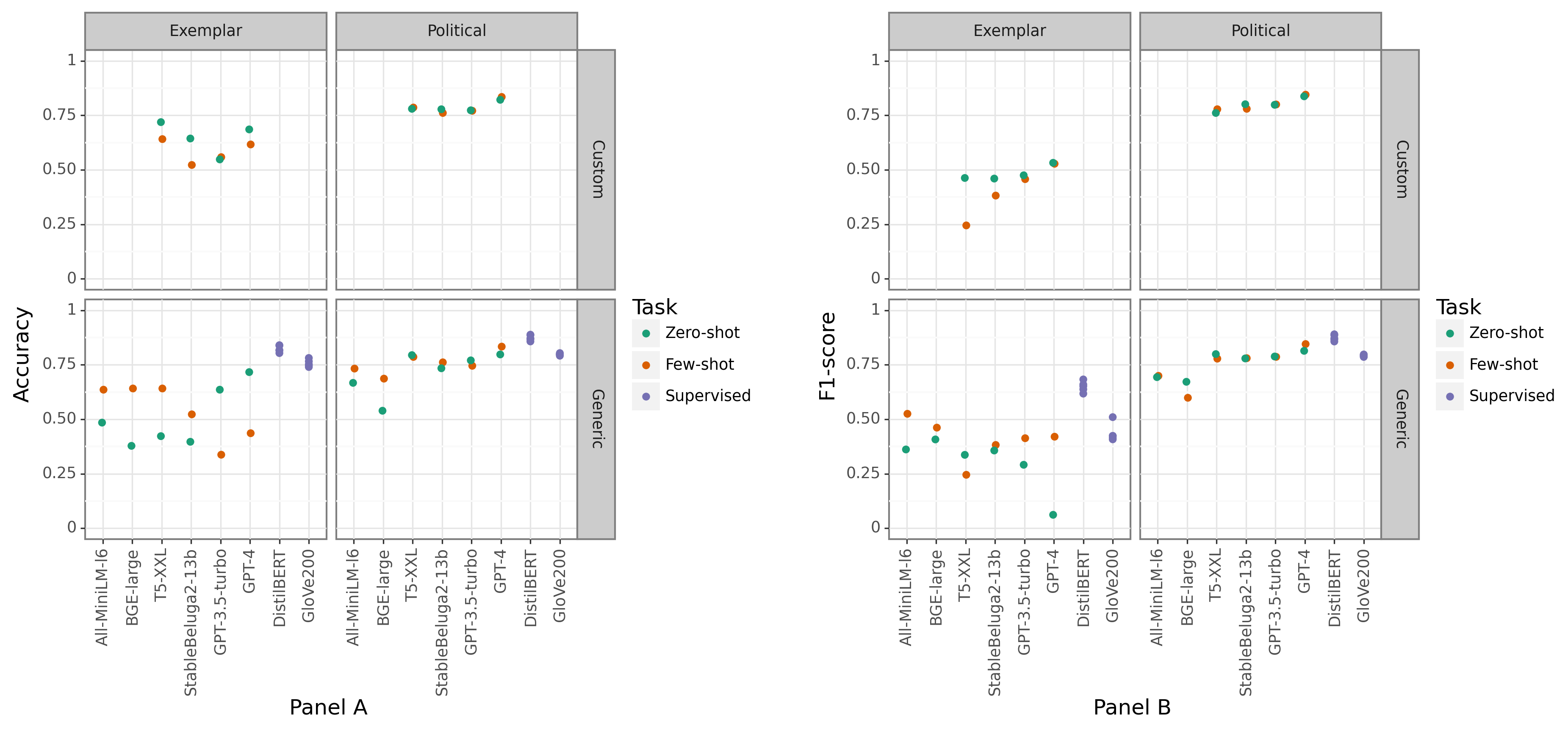
実験結果
リサーチクエスチョン
- RQ1OS LLMsとChatGPTは従来の監視付き分類子と比べて、単純な二値の社会科学注釈タスクで競争力のある性能を発揮するか。
- RQ2ゼロショット対ファew-shot、汎用対カスタムプロンプトはモデルファミリー間で性能にどう影響するか。
- RQ3テキスト注釈にLLMsを用いる際、分類精度とOpen Science原則の間にトレードオフはあるか。
- RQ4政治的タスクとexemplarの異なるタスク、およびモデル間でLLMsの一貫性と信頼性はどの程度か。
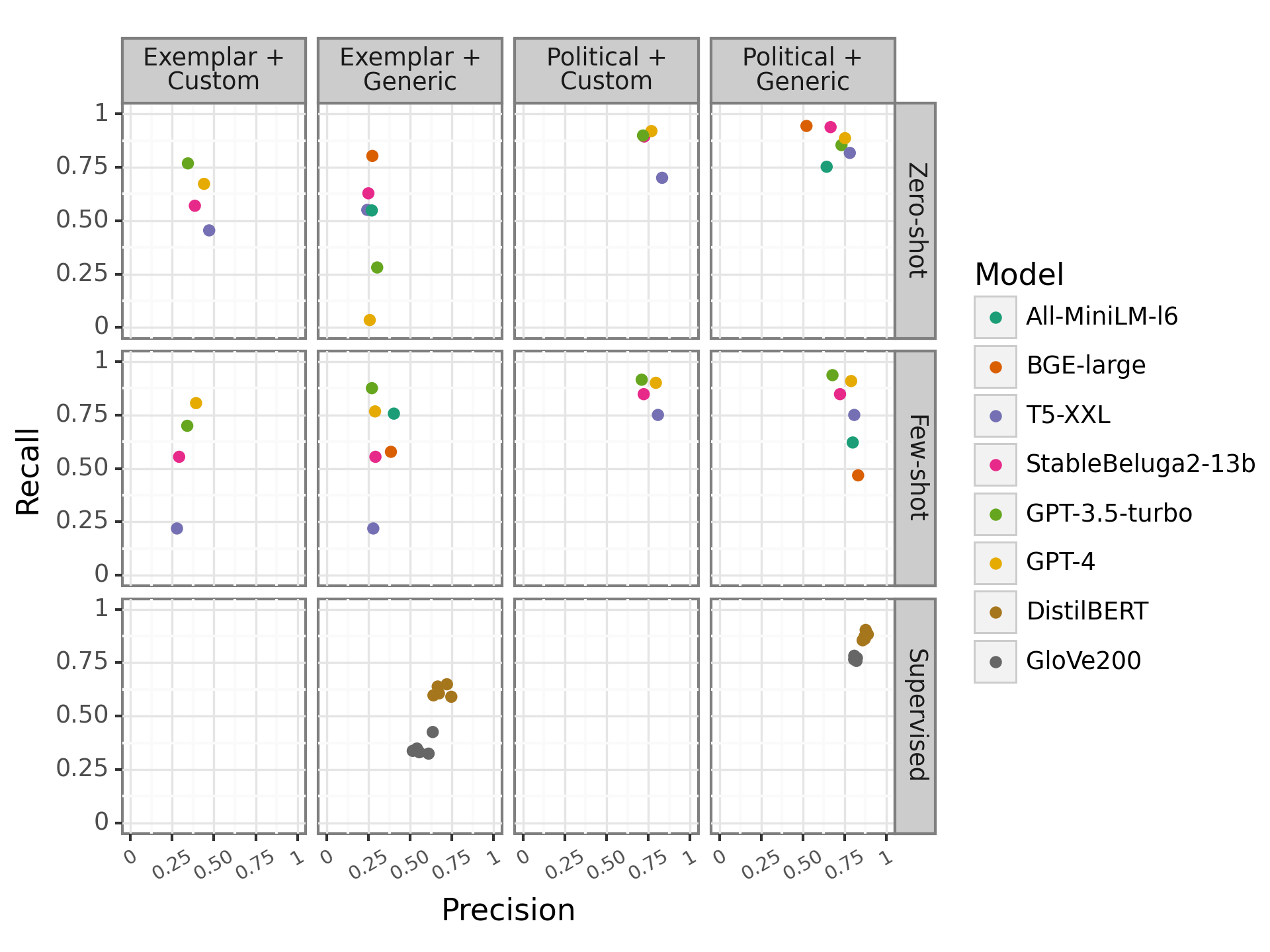
主な発見
- DistilBERTは二つのタスクとも最高の性能を達成する監督モデルである。
- OS LLMsはカスタムプロンプトで政治的コンテンツに対してChatGPTの性能に近づくことができるが、サイズは小さい。
- 全てのLLMはexemplarタスク(希少なカテゴリー)での性能が低く、変動が大きく、少数クラスの精度が低い。
- GPT-4は一部の設定で高い性能を示すことがあるが、ゼロショット誘導ではプロンプトタイプに依存してexemplar検出のリコールが非常に低くなる場合がある。
- 総じて、監督モデルはChatGPTおよびOS LLMsをタスクとプロンプト設定全体で一貫して上回る。
- カスタムプロンプティングとfew-shot学習はLLMの性能を改善することがあるが効果は一定ではない;小型オープンモデル(例:StableBeluga-13B)はローカルかつコスト効率の高い実験に実用的な利点を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。