[論文レビュー] Are Defenses for Graph Neural Networks Robust?
この論文は、7つの人気GNN防御を適応攻撃で評価し、ほとんどの防御がロバスト性の実質的な向上を提供せず、中には無防御ベースラインより悪い性能を示すものもあることを示している;また、強力な適応攻撃を設計するための方法論を提供し、ロバスト性のユニットテストを提案している。
A cursory reading of the literature suggests that we have made a lot of progress in designing effective adversarial defenses for Graph Neural Networks (GNNs). Yet, the standard methodology has a serious flaw - virtually all of the defenses are evaluated against non-adaptive attacks leading to overly optimistic robustness estimates. We perform a thorough robustness analysis of 7 of the most popular defenses spanning the entire spectrum of strategies, i.e., aimed at improving the graph, the architecture, or the training. The results are sobering - most defenses show no or only marginal improvement compared to an undefended baseline. We advocate using custom adaptive attacks as a gold standard and we outline the lessons we learned from successfully designing such attacks. Moreover, our diverse collection of perturbed graphs forms a (black-box) unit test offering a first glance at a model's robustness.
研究の動機と目的
- グラフ、アーキテクチャ、トレーニングカテゴリにわたるGNN頑健性のための49の防御を調査する。
- 代表的な7つの防御に対してカスタム適応攻撃を設計し、真の頑健性を測定する。
- GNN防御の頑健な評価のための透明性の高い方法論と実用的なガイドラインを提供する。
- 攻撃されたグラフのコレクション(頑健性ユニットテスト)を提供し、防御頑健性を迅速に評価する。
提案手法
- グラフ前処理、トレーニング変更、アーキテクチャ適応を組み込んだ拡張分類法を用いて防御を分類する。
- 完全な知識を前提とした強力な適応攻撃を開発・適用する(FGA、PGD、Metattack、Meta-PGDを含む)。
- グローバル(テストセット全体)およびローカル(各ノード) perturbation の予算付きL0摂動フレームワークを用い、 Poisoning と evasion の設定を含む。
- 攻撃力を最大化するために、攻撃損失関数(LM、TLM、PM などの対数マージン系)とハイパーパラメータを調整する。
- 勾配の問題や微分不可能な構成要素の扱い、モデル間の攻撃転送をどう扱うかを示し、堅牢な評価プロトコルを形成する。
- 適応攻撃が組み合わさった防御に対してどのように設計されるかを示すケーススタディ(SVD-GCN、ProGNN)を提供する。
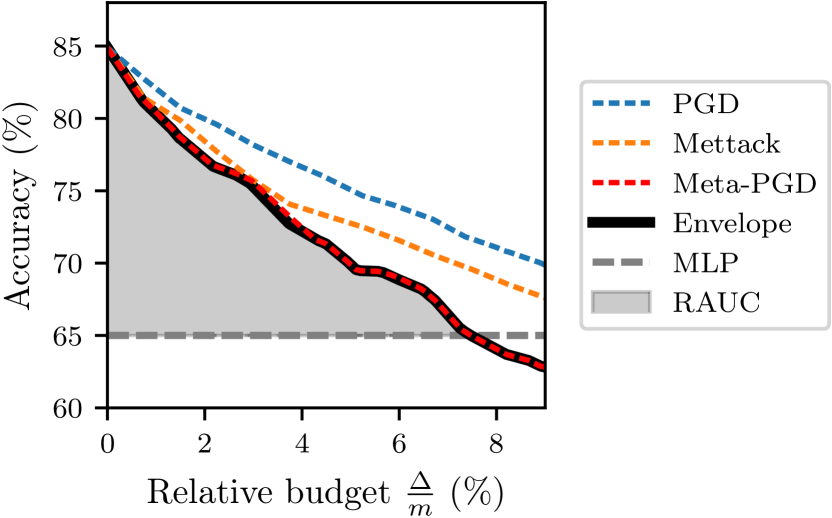
実験結果
リサーチクエスチョン
- RQ1適応的(ホワイトボックス)攻撃で評価した場合、人気のGNN防御はどれくらい頑健か?
- RQ2毒性付与と回避、ローカルおよびグローバル設定を横断して、強力な適応摂動に対して防御は意味のある頑健性の向上を提供するか?
- RQ3適応的攻撃の下で防御が示す共通の弱点は何か、複数の防御を迂回できる普遍的な摂動があるか?
- RQ4一連の摂動グラフはGNNの実用的な頑健性ユニットテストとして機能するか?
- RQ5Cora ML や Citeseer などのデータセットでは防御の性能と頑健性はどのように変化するか?
主な発見
- 適応攻撃は非適応評価と比較して防御の頑健性を平均約40%低下させる。
- 適応攻撃下で防御のほぼ半数が無防御のGCNより悪い性能を示し、いくつかの防御は頑健性の改善がほとんどない。
- 防御の有効性はデータセットに依存する;Cora MLとCiteseerで頑健性の向上が一様ではない。
- クリーンな精度が高いことがこの領域での頑健性の低下を意味するわけではなく、いくつかの頑健な防御は攻撃下でも基準精度を維持または上回る。
- 適応攻撃は防御ごとに異なる攻撃ベクトルを明らかにし、万能な摂動は存在しないことを示唆する;攻撃の転移性は一般的だが普遍的ではない。
- 著者らは頑健性ユニットテストを提供する:適応攻撃によって得られた摂動グラフはほとんどのケースで転移性があり、実用的な評価資源として機能する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。