[論文レビュー] Are Emergent Abilities in Large Language Models just In-Context Learning?
本論文は、18モデル(60M–175Bパラメータ)にわたる22タスクで emergent abilities を評価し、文脈内学習と指示調整をコントロールした上で、 emergent abilities は実際の emergent reasoning よりも文脈内学習で説明されることが大半であると結論づけている。
Large language models, comprising billions of parameters and pre-trained on extensive web-scale corpora, have been claimed to acquire certain capabilities without having been specifically trained on them. These capabilities, referred to as "emergent abilities," have been a driving force in discussions regarding the potentials and risks of language models. A key challenge in evaluating emergent abilities is that they are confounded by model competencies that arise through alternative prompting techniques, including in-context learning, which is the ability of models to complete a task based on a few examples. We present a novel theory that explains emergent abilities, taking into account their potential confounding factors, and rigorously substantiate this theory through over 1000 experiments. Our findings suggest that purported emergent abilities are not truly emergent, but result from a combination of in-context learning, model memory, and linguistic knowledge. Our work is a foundational step in explaining language model performance, providing a template for their efficient use and clarifying the paradox of their ability to excel in some instances while faltering in others. Thus, we demonstrate that their capabilities should not be overestimated.
研究の動機と目的
- 文脈内学習と指示調整を取り除いた場合に、どの能力が本当に出現的かを評価する。
- 出現的能力とプロンプティング技法の影響を区別する。
- 指示調整が文脈内学習を誘発するのか、あるいは真の推論能力を明らかにするのかを評価する。
提案手法
- 文脈内学習効果を取り除くため、非指示調整モデルをゼロショット設定で評価する。
- GPT、T5、Falcon、LLaMAといったモデルファミリを、指示調整の有無と関係なく、さまざまなスケールで比較する。
- 先行研究からの出現的・非出現的タスクを含む厳選されたセットを用い、バイアスを慎重に制御する。
- 結果を解釈するため、タスクを記憶可能性・形式的・機能的カテゴリに手動で分類する。
- 指示調整が、文脈内学習を活用して追加の能力を説明できるか(オッカムの剃刀)を分析する。
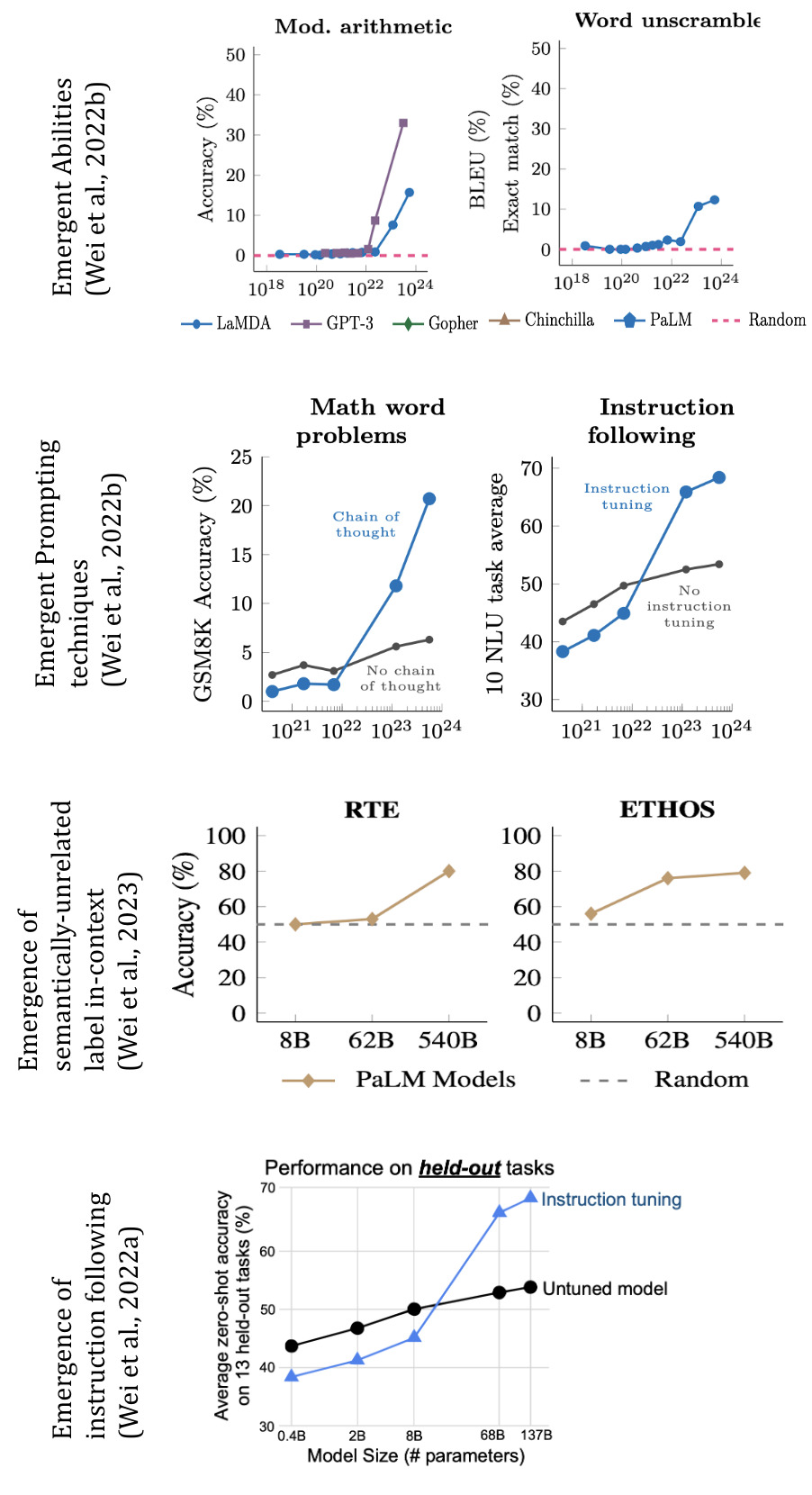
実験結果
リサーチクエスチョン
- RQ1文脈内学習と指示調整がない場合に、どの能力が本当に出現的か?
- RQ2指示調整は、観察される能力を説明するために文脈内学習を誘発または利用するのか?
- RQ3観察される能力は、形式的な言語能力、記憶、または機能的推論に起因するのか?
- RQ4より単純な説明(文脈内学習)で、指示調整モデルの向上を説明できるのか?
主な発見
- 出現的能力は、内在的な出現ではなく、主に文脈内学習に起因する。
- prompting techniquesなしでは推論能力の出現を示す証拠はない。
- 指示調整は、真の出現的推論よりも、主に文脈内能力を効率的に活用することでタスク性能を向上させる。
- 形式的言語能力と記憶は、これらの分析において機能的推論能力とは依然として区別される。
- 本研究は再現のためのコードと結果をオープンアクセスとして提供する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。