[論文レビュー] Are Sounds Sound for Phylogenetic Reconstruction?
本研究は、語彙的同系語、音響対応、およびそれらの結合から推定された系統樹を10の言語データセットで比較し、同系語ベースおよび連結データベースの系統樹が、音響ベースの系統樹より一般に金標準に近いことを示す。分子データに適したベイズ事前分布は言語分析に bias を生みうる可能性があり、音響ベースのアプローチはまれにしか同系語ベースを上回らない。
In traditional studies on language evolution, scholars often emphasize the importance of sound laws and sound correspondences for phylogenetic inference of language family trees. However, to date, computational approaches have typically not taken this potential into account. Most computational studies still rely on lexical cognates as major data source for phylogenetic reconstruction in linguistics, although there do exist a few studies in which authors praise the benefits of comparing words at the level of sound sequences. Building on (a) ten diverse datasets from different language families, and (b) state-of-the-art methods for automated cognate and sound correspondence detection, we test, for the first time, the performance of sound-based versus cognate-based approaches to phylogenetic reconstruction. Our results show that phylogenies reconstructed from lexical cognates are topologically closer, by approximately one third with respect to the generalized quartet distance on average, to the gold standard phylogenies than phylogenies reconstructed from sound correspondences.
研究の動機と目的
- 音声対応パターンが、語彙的同系語よりも正確な言語系統樹を生み出すかを評価する。
- 同系語検出と音響対応推論を自動化し、ベイズおよび機械学習フレームワーク内で評価する。
- ベイズ結果を最大尤度解析で検証し、事前分布の影響を検討する。
- 金標準の Glottolog 木を用いて、音響ベースの系統樹と同系語ベースの系統樹を比較する。
- データ型の結合が、より優れた系統信号を提供するかを調査する。
提案手法
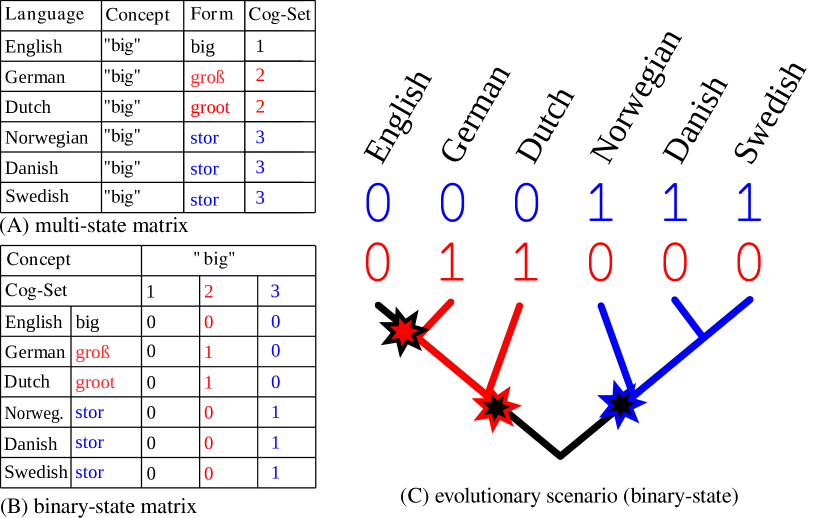
- 同系語判断と音響対応パターンを、二値の有無行列として符号化する。
- 特徴の獲得/喪失を時間可逆な二値状態CTMCでモデル化する。
- 標準化された事前分布を用いて MrBayes でベイズ系統推定を実行し、alpha形状事前分布を検討する。
- RAxML-NG を用いて BIN+G の下で ML系統推定を実行し、レート異質性のために ML推定された alpha を用いる。
- ノイズを減らすために音声整列をトリミングし、 LingRex/LingPy で音響対応を計算する。Glottolog 木との Generalized Quartet Distance (GQD)で評価する。
- 三つのデータセット(同系語、音響対応、結合行列)を検証する。
実験結果
リサーチクエスチョン
- RQ1同系語データから推定された系統樹は、音響対応から推定された系統樹より金標準の木とより良く一致するか。
- RQ2音響対応ベースの系統樹が、同系語ベースの系統樹より金標準に近づくことはあるか。
- RQ3同系語データと音響データを結合すると、いずれか単独のデータタイプよりも優れた系統樹が得られるか。
- RQ4分子データ用に調整されたベイズ事前分布は言語系統結果に偏りを生むか、ML解析でその偏りを検出できるか。
- RQ5複数データセットにおいて、Generalized Quartet Distance (GQD) の観点から、音響ベースの系統樹は同系語ベースの系統樹とどのように比較されるか?
主な発見
- 同系語データと結合データ由来の系統樹は、精度の範囲がほぼ同程度であり、音響ベースの樹より一般に金標準に近い。
- 音響対応ベースの系統樹は、10データセットを通じてベイズ分析で最高の結果を決して出さなかった。
- 結合データは10データセットのうち7つで最高の結果を示し、残りの3つは同系語データが最良。
- ML分析は大部分でベイズ結果を裏付け、同系語および結合ベースの系統樹が音響ベースの樹より金標準に近いことを示している。
- デフォルトの分子事前分布は言語のベイズ結果に偏りを生む可能性がある。ML解析を補完することでこのような偏りの診断に役立つ。
- この研究は、言語データにベイズ法を適用する際に、事前分布およびモデリングの選択を再評価する必要性を浮き彫りにしている。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。