[論文レビュー] AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn
AssistGPT は、言語とコード推論(計画、実行、検査、学習)を組み合わせて複数のツールを統括し、複雑な視覚タスクと長尺のビデオ推論に取り組む一般的なマルチモーダルAIシステムです。A-OKVQA および NExT-QA のベンチマークで最先端の結果を達成します。
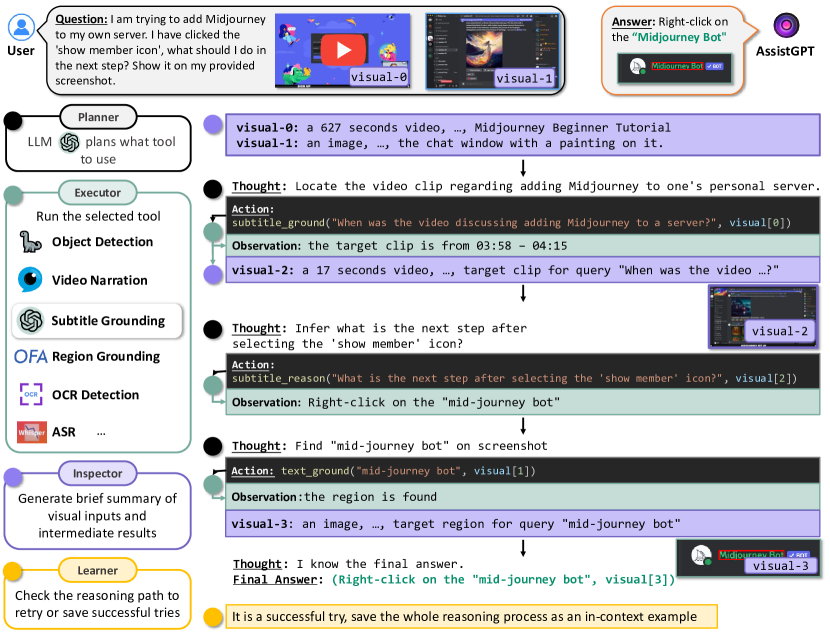
Recent research on Large Language Models (LLMs) has led to remarkable advancements in general NLP AI assistants. Some studies have further explored the use of LLMs for planning and invoking models or APIs to address more general multi-modal user queries. Despite this progress, complex visual-based tasks still remain challenging due to the diverse nature of visual tasks. This diversity is reflected in two aspects: 1) Reasoning paths. For many real-life applications, it is hard to accurately decompose a query simply by examining the query itself. Planning based on the specific visual content and the results of each step is usually required. 2) Flexible inputs and intermediate results. Input forms could be flexible for in-the-wild cases, and involves not only a single image or video but a mixture of videos and images, e.g., a user-view image with some reference videos. Besides, a complex reasoning process will also generate diverse multimodal intermediate results, e.g., video narrations, segmented video clips, etc. To address such general cases, we propose a multi-modal AI assistant, AssistGPT, with an interleaved code and language reasoning approach called Plan, Execute, Inspect, and Learn (PEIL) to integrate LLMs with various tools. Specifically, the Planner is capable of using natural language to plan which tool in Executor should do next based on the current reasoning progress. Inspector is an efficient memory manager to assist the Planner to feed proper visual information into a specific tool. Finally, since the entire reasoning process is complex and flexible, a Learner is designed to enable the model to autonomously explore and discover the optimal solution. We conducted experiments on A-OKVQA and NExT-QA benchmarks, achieving state-of-the-art results. Moreover, showcases demonstrate the ability of our system to handle questions far more complex than those found in the benchmarks.
研究の動機と目的
- 多様な視覚入力と単一画像推論を超える柔軟なタスクに対応できる汎用マルチモーダルアシスタントの必要性を動機づける。
- 言語とコードを組み合わせてツールの利用を計画し、中間結果を管理する四部構成の PEIL フレームワークを提案する。
- A-OKVQA および NExT-QA での最先端結果を通じてシステムの有効性を示し、複雑な現実世界の場面への対応を示す。
- Learner コンポーネントが文脈内学習と成功したトレースの再利用を通じて自己改善を可能にする方法を示す。
提案手法
- Planner は LLM(GPT-4)を用いて次の一歩を guiding する自然言語の思考と外部ツールを呼び出す構造化された Action の二部出力を生成する。
- Executor はツール固有のコードを検証・実行し、結果を後処理して観察を生成し、これを Planner にフィードバックする。
- Inspector は視覚入力と中間結果のメタデータと要約を記録して、Planner がソースとツールを選択する際の補助を行う。
- Learner は推論を評価し、自己チェックを実施し、将来の予測を改善するために成功したトレースを文脈内の例として保存する。
実験結果
リサーチクエスチョン
- RQ1AssistGPT が言語とコードの計画の交互によって複雑なマルチモーダルタスクで強力な性能を達成できるか。
- RQ2各 PEIL コンポーネント(Planner、Executor、Inspector、Learner)がタスク性能と頑健性に与える影響は何か。
- RQ3AssistGPT は A-OKVQA や NExT-QA のベンチマークで既存のマルチモーダルシステムとどう比較されるか。
- RQ4Learner が時間とともに意味のある文脈内学習と自己改善を可能にするか。
- RQ5柔軟な入力(画像、動画、書き起こし、字幕)を Inspector とツールセットが効果的に扱えるか。
主な発見
| Model | D.A. | M.C. |
|---|---|---|
| AssistGPT (BLIP2 FlanT5 XL) | 42.6 | 73.7 |
| AssistGPT (Ins.BLIP Vicuna-7B) | 44.3 | 74.7 |
| InstructBLIP Vicuna-7B | 64.0 | 75.7 |
| PromptCap | 56.3 | 73.2 |
| GPV-2 | 48.6 | 60.3 |
| LXMERT | 30.7 | 51.4 |
| KRISP | 33.7 | 51.9 |
- AssistGPT のバリアントはマルチチョイスの A-OKVQA で競争力のある、または最先端に近い結果を達成し、直接回答タスクでも比較可能。
- アブレーションにより、Learner コンポーネントを含む言語とコード推論の交互(PEIL)が最も強い性能を生み、推論のみや純粋な ReAct ベースラインを上回る。
- NExT-QA では、因果・時間的・記述的質問応答スコアで競争力を示し、いくつかの最近のベースラインを上回る。
- Learner の自己チェックと GT チェックのバリアントは頑健性と文脈内学習能力を著しく改善し、将来のクエリのために成功したトレースを保存。
- 従来の LLM 主導のモジュラーシステムと比較して、複雑で複数ソースの視覚入力と長尺のビデオ推論の取り扱いが改善。
- 定性的結果は、複雑な質問の効果的な分解と、計画の修正とツールの再呼び出しによる自己訂正行動を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。