[論文レビュー] Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
ACEはMAPPOを非同期設定へ拡張し、行動遅延のランダム化とマルチタワーCNNポリシーを用いてリアルタイムの協調探索を可能にする。グリッド、実世界、そしてHabitat環境において、計画ベースおよび同期MARLのベースラインを上回る。
We consider the problem of cooperative exploration where multiple robots need to cooperatively explore an unknown region as fast as possible. Multi-agent reinforcement learning (MARL) has recently become a trending paradigm for solving this challenge. However, existing MARL-based methods adopt action-making steps as the metric for exploration efficiency by assuming all the agents are acting in a fully synchronous manner: i.e., every single agent produces an action simultaneously and every single action is executed instantaneously at each time step. Despite its mathematical simplicity, such a synchronous MARL formulation can be problematic for real-world robotic applications. It can be typical that different robots may take slightly different wall-clock times to accomplish an atomic action or even periodically get lost due to hardware issues. Simply waiting for every robot being ready for the next action can be particularly time-inefficient. Therefore, we propose an asynchronous MARL solution, Asynchronous Coordination Explorer (ACE), to tackle this real-world challenge. We first extend a classical MARL algorithm, multi-agent PPO (MAPPO), to the asynchronous setting and additionally apply action-delay randomization to enforce the learned policy to generalize better to varying action delays in the real world. Moreover, each navigation agent is represented as a team-size-invariant CNN-based policy, which greatly benefits real-robot deployment by handling possible robot lost and allows bandwidth-efficient intra-agent communication through low-dimensional CNN features. We first validate our approach in a grid-based scenario. Both simulation and real-robot results show that ACE reduces over 10% actual exploration time compared with classical approaches. We also apply our framework to a high-fidelity visual-based environment, Habitat, achieving 28% improvement in exploration efficiency.
研究の動機と目的
- 非同期の行動実行下で、複数の異種ロボットによるリアルタイムの協調探索を促進する。
- 探索を停滞させずに行動遅延とオフラインエージェントを扱う非同期MARLフレームワークを開発する。
- チーム規模に応じてスケールし、帯域幅を最小化する効率的な通信ポリシーを提案する。
- グリッドベース、実世界、およびHabitat(視覚ベース)環境において優れた探索効率を実証する。
提案手法
- MAPPOをAsync-MAPPOへ拡張し、非同期の行動作成とエージェントごとの経験バッファをサポートする。
- 異なる遅延に対するシミュレーションから実機への一般化を改善するため、シミュレーション中に行動遅延のランダム化を導入する。
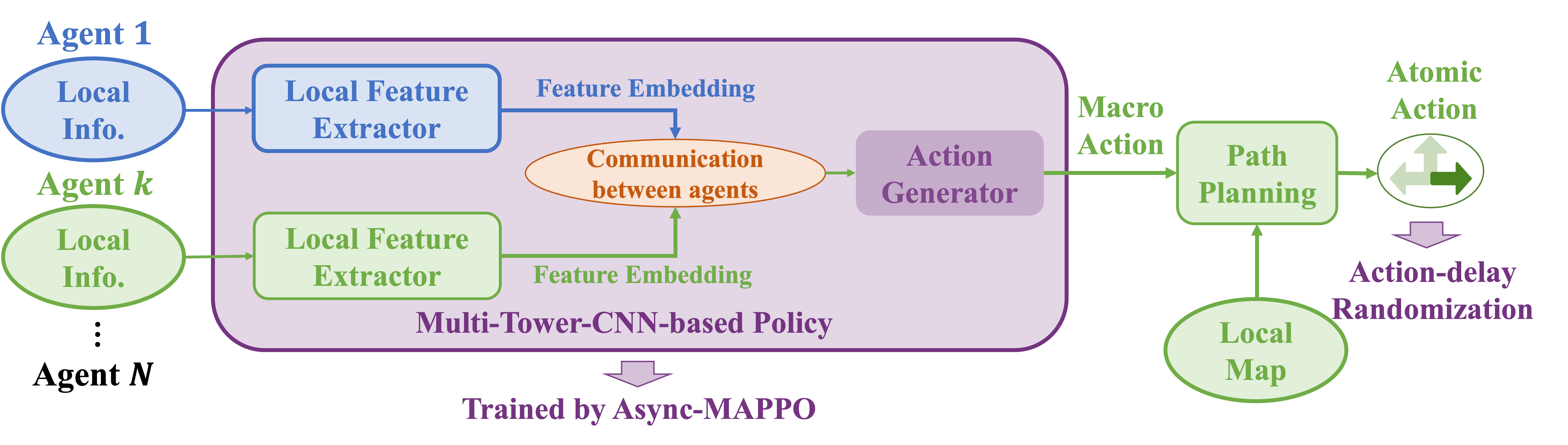
- 局所CNN特徴、注意機構を用いた関係エンコーダ、およびマクロ行動を出力するデコーダを備えたMulti-tower-CNNベースのポリシー(MCP)を提案する。
- グローバル目標としてのマクロ行動とアトミック行動を用いたDec-POSMDP定式化を採用し、二階層の行動実行を可能にする。
- 重み共有ポリシーと限定特徴量通信を用いて、チームサイズの変動に対応し、実世界での堅牢なデプロイを実現する。

実験結果
リサーチクエスチョン
- RQ1MARLを、複数ロボットの協調探索のための非同期行動実行へどのように適応させられるか?
- RQ2行動遅延のランダム化は、シミュレーションから実機への転送と現実世界の遅延に対する頑健性を向上させるか?
- RQ3CNNベースでサイズ不変のポリシーは、限られた帯域幅で複数のロボットを効率的に協調させることができるか?
- RQ4異なる環境における非同期ACEと計画ベースおよび同期MARLベースラインの性能向上はどれほどか?
- RQ5探索中にエージェントがオフラインになる状況をACEはどう処理するか?
主な発見
- ACEは従来の計画ベース手法と比較して実世界の探索時間を10%以上短縮する。
- Habitat(視覚ベース環境)で探索効率を28%改善する。
- 2台のロボットを用いた実世界試験で、ACEはMAPPOベースラインと比較して探索時間を10.07%短縮する。
- 実世界実験で、最速の計画ベース手法(Nearest)に対して探索時間を33.86%短縮する。
- エージェント喪失シナリオ(N1からN2)に対して、探索を約10%速くし、ベースラインと比べて重複を低く一般化する。
- 設定を跨いで、ACSを競合レベルに維持しつつ重複を抑え、より速い完了を達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。