[論文レビュー] AtMan: Understanding Transformer Predictions Through Memory Efficient Attention Manipulation
AtManは注意力スコアを操作することでトランスフォーマーの予測を導く、メモリ効率の高い摂動ベースのXAI手法を導入します。これにより、追加メモリを最小限に抑えつつ、テキストおよび画像-テキストタスクにおいて勾配ベースのベースラインより精度を向上させ、広範なマルチモーダルモデルの説明が可能になります。
Generative transformer models have become increasingly complex, with large numbers of parameters and the ability to process multiple input modalities. Current methods for explaining their predictions are resource-intensive. Most crucially, they require prohibitively large amounts of extra memory, since they rely on backpropagation which allocates almost twice as much GPU memory as the forward pass. This makes it difficult, if not impossible, to use them in production. We present AtMan that provides explanations of generative transformer models at almost no extra cost. Specifically, AtMan is a modality-agnostic perturbation method that manipulates the attention mechanisms of transformers to produce relevance maps for the input with respect to the output prediction. Instead of using backpropagation, AtMan applies a parallelizable token-based search method based on cosine similarity neighborhood in the embedding space. Our exhaustive experiments on text and image-text benchmarks demonstrate that AtMan outperforms current state-of-the-art gradient-based methods on several metrics while being computationally efficient. As such, AtMan is suitable for use in large model inference deployments.
研究の動機と目的
- バックプロパゲーションに基づくXAIがメモリ集約的である大規模生成型トランスフォーマーにおいて、スケーラブルな説明可能性の必要性を動機づける。
- オープン語彙生成の入力関連度マップを生成する、メモリ効率の高い注意機構操作を伴う摂動法としてAtManを提案する。
- AtManが摂動要件を低減し、追加のメモリオーバーヘッドなしに大規模モデルへスケールできることを示す。
- AtManをテキストおよび画像および画像-テキストのベンチマークで評価し、勾配ベースのXAI手法と同等またはそれ以上の性能を示す。
提案手法
- 摂動を介してモデルの出力に最も影響を与える入力部分を特定することで説明可能性を定式化する。
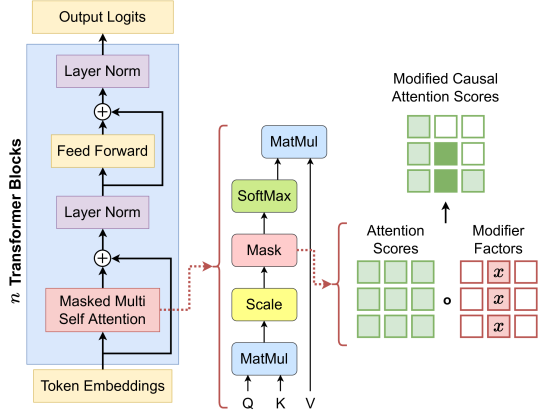
- 摂動空間を入力空間から埋め込みトークン空間へ移し、ウェイトではなく注意スコアを摂動させる。
- 単一トークンの注意抑制を定義する。特定のトークンの注意寄与を係数fでスケールして予測を誘導する。
- 埋め込み空間におけるコサイン類似度を用いた相関トークン抑制へ拡張し、トークン間の冗長性を抑制する。
- 禁止行列を用いて前ソフトマックスの注意Hを各トークンごとに修正する閉形式の方程式(Eq. 4)と、影響スコアのベクトルとして説明を蓄積する方程式(Eq. 5)を提供する。
- トークン近傍を考慮するために相関トークン抑制(Eq. 6)を適用し、ノイズの多い寄与の説明を減らす。
- テキストおよび画像言語モデルを対象とした実験によりスケーラビリティとメモリ効率を実証し、勾配ベースXAIのベースラインと比較する。

実験結果
リサーチクエスチョン
- RQ1AtManは言語モデルおよび視覚言語モデルにおいて、勾配ベースXAI手法と比較して競争力のある説明を提供できるか。
- RQ2AtManは大規模自己回帰トランスフォーマーやマルチモーダルモデルに対して、過度なメモリコストなしにスケール可能か。
- RQ3相関トークン抑制はマルチモーダル設定における説明の堅牢性を向上させるか。
- RQ4QA/VQAベンチマークにおけるAtManの説明は、人間が注釈した説明信号や真の説明信号と整合するか。
主な発見
- AtManはテキストQAおよび画像-テキストVQAベンチマークで平均適合率(mean average precision)および関連指標で勾配ベースのベースラインを上回る。
- AtManはフォワードパスと同程度のメモリ使用量を維持し、勾配ベースXAIがメモリ制約で失敗する大規模モデルへの展開を可能にする。
- AtManはMAGMAバリアント(6B, 13B, 30B)およびBLIPで競争力のある性能を示し、モデル非依存の適用性を示す。
- 相関トークン抑制は埋め込み空間におけるコサイン類似度を活用して冗長情報を抑制し、説明品質を向上させる。
- SQuAD(テキスト)とOpenImages(視覚)での実験は、ほとんどの評価設定でIxG、IG、GradCAM、CheferよりAtManがより高い適合度/再現率を示す。
- 大規模ハードウェア(80GB A100)上で、勾配ベース手法のメモリ制限を超える場所でもAtManは実行可能であり、スケーラビリティを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。