[論文レビュー] Attacking Large Language Models with Projected Gradient Descent
論文は連続的に緩和されたトークン列上で動作するLLM向けのProjected Gradient Descent (PGD) 攻撃を提示し、離散最適化手法と同程度の攻撃力を達成しつつ最大10倍速く実行できる。
Current LLM alignment methods are readily broken through specifically crafted adversarial prompts. While crafting adversarial prompts using discrete optimization is highly effective, such attacks typically use more than 100,000 LLM calls. This high computational cost makes them unsuitable for, e.g., quantitative analyses and adversarial training. To remedy this, we revisit Projected Gradient Descent (PGD) on the continuously relaxed input prompt. Although previous attempts with ordinary gradient-based attacks largely failed, we show that carefully controlling the error introduced by the continuous relaxation tremendously boosts their efficacy. Our PGD for LLMs is up to one order of magnitude faster than state-of-the-art discrete optimization to achieve the same devastating attack results.
研究の動機と目的
- LLMsの自動的なレッドチーミングを効率的に動機付け、実現する。
- 連続リラクゼーションを用いた勾配ベースの最適化が離散的な攻撃と効果で同等であることを示す。
- 最適化を確率的なシンプソに保ち、リラクゼーション誤差を制御する射影ベースのフレームワークを開発する。
- 大規模評価と敵対的訓練のための最先端攻撃に比べた効率向上を示す。
提案手法
- 確率的シンプソ上でワンホット入力トークンの連続リラクゼーションを定式化する。
- リラクゼーションされた入力に勾配ベースの更新を適用し、各ステップ後にシンプソへ再射影する。
- リラクゼーション誤差を抑え離散性を促進するため、エントロピー(ジニ系)射影を用いる。
- トークンマスクによる微分可能な長さの柔軟性を導入し、アテンションにおけるトークンの滑らかな挿入/削除を可能にする。
- リラクゼーション後に各トークンでargmaxを取って離散化し、得られたシーケンス上の攻撃目的を評価する。
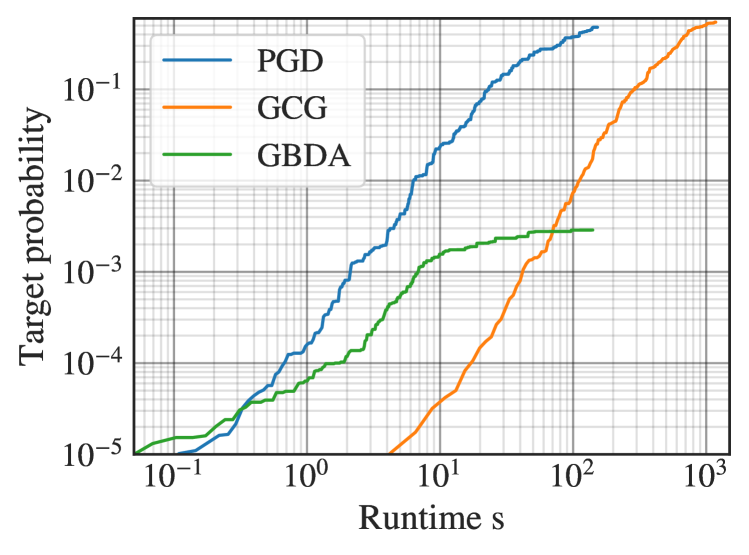
実験結果
リサーチクエスチョン
- RQ1勾配ベースの最適化と連続リラクゼーションを用いた手法は、ジャイルブレイキングタスクで整合性を持つLLMsを効果的に攻撃できるか。
- RQ2PGDは攻撃の効果と計算効率の点で離散最適化手法とどう比較されるか。
- RQ3エントロピー射影はリラクゼーション誤差を打ち消すことで信頼性を向上させるか。
- RQ4可変シーケンス長を許容することで攻撃性能はさらに向上するか。
主な発見
| Attack | ASR @ 60 s | Iter. / s |
|---|---|---|
| PGD | 87 % | 28.2 |
| GCG | 83 % | 0.3 |
| GBDA | 40 % | 29.3 |
- PGDは最先端の離散最適化手法と同等かそれ以上の攻撃力を、実行時間を最大でオーダー1桁分短縮して達成する。
- 行動ジャイルブレイクタスクでは、PGDは60秒時点で87%の攻撃成功率を達成し、GCGは83%、GBDAは40%であった。
- PGDは探索空間を約65,000から各位置につき約10の候補トークンへと削減する。
- アブレーションからのクロスエントロピーの結果: 0.092±0.014(リラクゼーションなし)、0.085±0.010(エントロピー射影なしリラクゼーション)、0.078±0.009(エントロピー射影ありリラクゼーション)。
- PGDの効率優位性はVicuna 7B、Falcon 7B、Falcon 7B Instructモデル全体で示される。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。