[論文レビュー] Attending to Graph Transformers
この論文は、グラフ変換器アーキテクチャの分類法と実証評価を提供し、構造/位置エンコーディング、入力特徴、トークン化、伝搬戦略を強調し、グラフ構造を回復する能力とヘテロファリーへの対応を評価します。
Recently, transformer architectures for graphs emerged as an alternative to established techniques for machine learning with graphs, such as (message-passing) graph neural networks. So far, they have shown promising empirical results, e.g., on molecular prediction datasets, often attributed to their ability to circumvent graph neural networks' shortcomings, such as over-smoothing and over-squashing. Here, we derive a taxonomy of graph transformer architectures, bringing some order to this emerging field. We overview their theoretical properties, survey structural and positional encodings, and discuss extensions for important graph classes, e.g., 3D molecular graphs. Empirically, we probe how well graph transformers can recover various graph properties, how well they can deal with heterophilic graphs, and to what extent they prevent over-squashing. Further, we outline open challenges and research direction to stimulate future work. Our code is available at https://github.com/luis-mueller/probing-graph-transformers.
研究の動機と目的
- Provide a structured overview of state-of-the-art graph transformer (GT) architectures and their theoretical properties.
- Survey structural and positional encodings and their impact on GT expressivity.
- Examine how GTs handle non-geometric vs geometric (3D) graph features.
- Evaluate GTs on structural awareness, heterophily, and over-squashing phenomena.
- Outline open challenges and future research directions in graph transformers.
提案手法
- Derive a taxonomy of GT architectures across encodings, input features, tokenization, and propagation.
- Discuss theoretical expressivity of GTs and dependence on structural/positional biases.
- Survey and categorize structural and positional encodings (local/global/relative).
- Analyze input feature regimes (non-geometric vs geometric) and geometric equivariance approaches.
- Examine tokenization strategies (nodes, edges, subgraphs) and their computational trade-offs.
- Review propagation schemes (global, sparse, hybrid) and scaling techniques (linear/ kernelized attention).
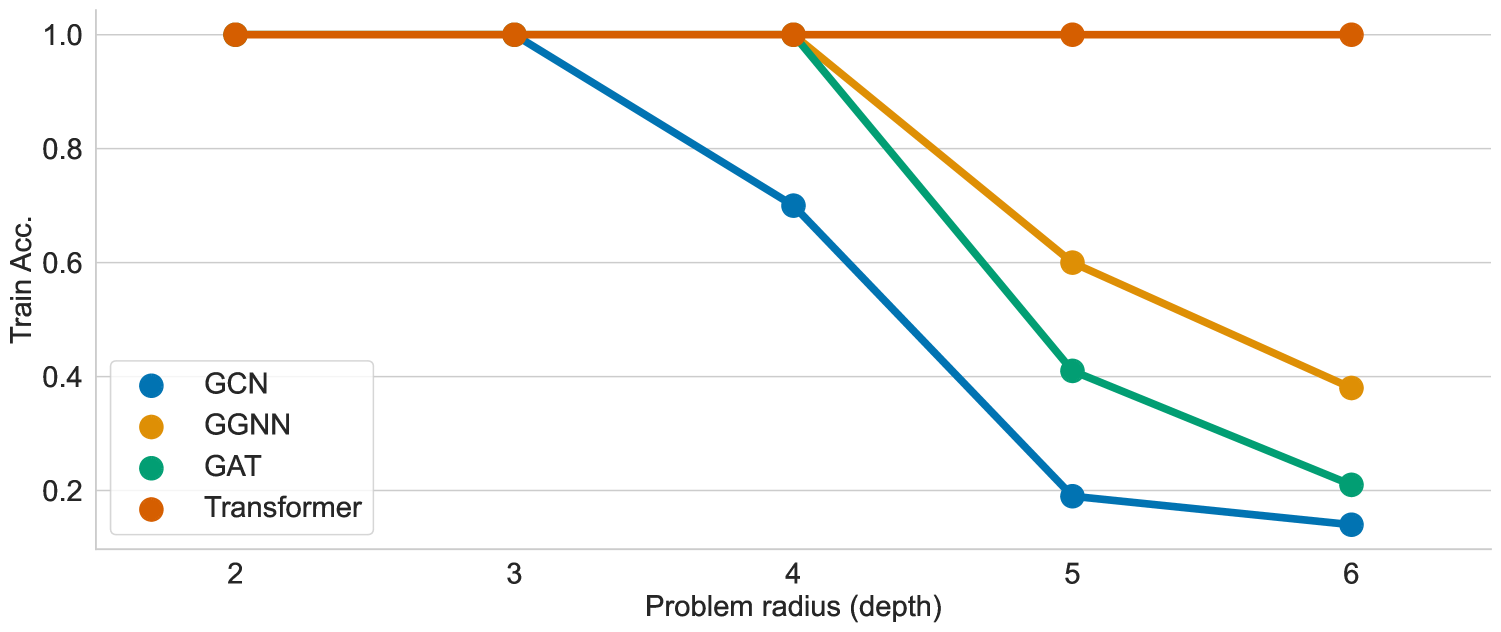
実験結果
リサーチクエスチョン
- RQ1How do structural and positional encodings affect GT expressivity and ability to distinguish non-isomorphic graphs?
- RQ2Can GTs mitigate over-smoothing and over-squashing, especially on heterophilic graphs?
- RQ3What are the practical trade-offs of node-only vs edge-inclusive vs subgraph tokenization for GTs?
- RQ4How do geometric features (3D coordinates) and SE(3)/E(3) equivariance influence GT performance?
- RQ5What are the effective propagation strategies to scale GTs to larger graphs while preserving accuracy?
主な発見
| Model (PE/SE type) | アクター | Cornell | Texas | Wisconsin | Chameleon | Squirrel |
|---|---|---|---|---|---|---|
| Geom-GCN (DEG) | 31.59 ±1.15 | 60.54 ±3.67 | 64.51 ±3.66 | 66.76 ±2.72 | 60.00 ±2.81 | |
| GCN (no PE/SE) | 33.92 ±0.63 | 53.78 ±3.07 | 65.95 ±3.67 | 66.67 ±2.63 | 43.14 ±1.33 | |
| GCN (LapPE) | 34.30 ±1.12 | 56.22 ±2.65 | 65.95 ±3.67 | 66.47 ±1.37 | 43.53 ±1.45 | |
| GCN (RWSE) | 33.69 ±1.07 | 53.78 ±4.09 | 62.97 ±3.21 | 69.41 ±2.66 | 43.84 ±1.68 | |
| GCN (DEG) | 33.99 ±0.91 | 53.51 ±2.65 | 66.76 ±2.72 | 67.26 ±1.53 | 46.36 ±2.07 | |
| GPS GCN+Transformer (LapPE) | 37.68 ±0.52 | 66.22 ±3.87 | 75.41 ±1.46 | 74.71 ±2.97 | 48.57 ±1.02 | |
| GPS GCN+Transformer (RWSE) | 36.95 ±0.65 | 65.14 ±5.73 | 73.51 ±2.65 | 78.04 ±2.88 | 47.57 ±0.90 | |
| GPS GCN+Transformer (DEG) | 36.91 ±0.56 | 64.05 ±2.43 | 73.51 ±3.59 | 75.49 ±4.23 | 52.59 ±1.81 | |
| Transformer (LapPE) | 38.43 ±0.87 | 69.46 ±1.73 | 77.84 ±1.08 | 76.08 ±1.92 | 49.69 ±1.11 | |
| Transformer (RWSE) | 38.13 ±0.63 | 70.81 ±2.02 | 77.57 ±1.24 | 80.20 ±2.23 | 49.45 ±1.34 | |
| Transformer (DEG) | 37.39 ±0.50 | 71.89 ±2.48 | 77.30 ±1.32 | 79.80 ±0.90 | 56.18 ±0.83 | |
| Graphormer (DEG only) | 36.91 ±0.85 | 68.38 ±1.73 | 76.76 ±1.79 | 77.06 ±1.97 | 54.08 ±2.35 | |
| Graphormer (DEG, attn. bias) | 36.69 ±0.70 | 68.38 ±1.73 | 76.22 ±2.36 | 77.65 ±2.00 | 53.84 ±2.32 |
- GTs without expressive encodings have limited graph-structure discernment, reinforcing the need for structural/positional biases.
- Several encodings (RWSE, LapPE) and attention biases (shortest-path, edge representations) enhance structural awareness and task performance.
- Hybrid propagation (local GNN + global attention) often yields strong results, balancing scalability and expressivity.
- Geometric GTs with SE(3)/E(3) equivariance and distance-based attention improve molecular property tasks and 3D graph modeling.
- Empirical results show varying performance across tasks, with baselines (vanilla transformers) lagging behind structurally biased GTs on structural/heterophily benchmarks.
- Table 3 (heterophilic datasets) demonstrates substantial performance gaps between GNN baselines and GT variants with structural encodings.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。