[論文レビュー] Augmenting Self-attention with Persistent Memory
論文は、文脈的自己注意とキー-バリューの永続的メモリをブレンドする全注意層を導入し、従来のフィードフォワードサブレイヤを置換して、文字および語彙ベンチマークで競争力のある言語モデリング結果を達成します。
Transformer networks have lead to important progress in language modeling and machine translation. These models include two consecutive modules, a feed-forward layer and a self-attention layer. The latter allows the network to capture long term dependencies and are often regarded as the key ingredient in the success of Transformers. Building upon this intuition, we propose a new model that solely consists of attention layers. More precisely, we augment the self-attention layers with persistent memory vectors that play a similar role as the feed-forward layer. Thanks to these vectors, we can remove the feed-forward layer without degrading the performance of a transformer. Our evaluation shows the benefits brought by our model on standard character and word level language modeling benchmarks.
研究の動機と目的
- Motivate simplifying transformer architectures by replacing the feedforward sublayer with persistent memory.
- Propose an all-attention layer that unifies contextual and persistent information through attention.
- Show that persistent memory can replace feedforward components without performance loss.
- Evaluate on standard character and word language modeling benchmarks and compare with transformer baselines.
提案手法
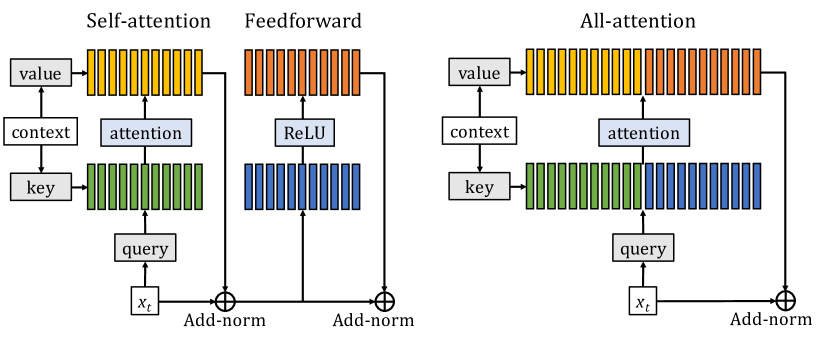
- Reformulate the feedforward sublayer as an attention mechanism and merge it with self-attention.
- Introduce a set of persistent key-value vectors that act as uncontextual, task-wide memory.
- Construct an all-attention layer that concatenates context keys/values with persistent memory keys/values.
- Apply multi-head attention over both contextual and persistent vectors with AddNorm residuals.
- Use relative position encodings and adaptive context mechanisms to handle long sequences and large vocabularies.
- Train and evaluate on character- and word-level language modeling benchmarks with standard optimization and regularization settings.
実験結果
リサーチクエスチョン
- RQ1Can persistent memory vectors replace the feedforward sublayer in Transformer architectures without performance loss?
- RQ2Does a unified all-attention layer that attends to both context and persistent memory improve language modeling performance on benchmark datasets?
- RQ3How do different integration strategies for persistent memory affect model effectiveness?
- RQ4What are the computational and parameter implications of replacing feedforward layers with persistent memory in deep transformer stacks?
主な発見
| Model | #Params | test bpc | dev bpc | test ppl | dev ppl |
|---|---|---|---|---|---|
| All-attention network + adaptive span (Small) (enwik8) | 39M | 1.01 | |||
| All-attention network + adaptive span (Large) (enwik8) | 114M | 0.98 | |||
| All-attention network + adaptive span (Small) (text8) | 38M | 1.11 | 1.05 | 1.11 | 1.05 |
| All-attention network + adaptive span (Large) (text8) | 114M | 1.08 | 1.02 | 1.08 | 1.02 |
| All-attention network + adaptive span (Small) (WikiText-103) | 133M | 20.6 | 19.7 | 20.6 | 19.7 |
| Transformer-XL Standard (large comparison) (WikiText-103) | 257M | 18.3 | 17.7 | 18.3 | 17.7 |
- The all-attention network with persistent memory achieves competitive to state-of-the-art results on character-level benchmarks with fewer parameters in some settings.
- On enwik8 (character level), the large all-attention model with adaptive span attains performance at 0.98–1.01 bpc range, often matching or surpassing comparable Transformer baselines.
- On text8 (character level), the small and large all-attention variants closely match or exceed the best reported results with fewer parameters in the large setting (e.g., 0.98–1.08 bpc).
- On WikiText-103 (word level), the all-attention network with adaptive span outperforms prior small-model results by several perplexity points (e.g., about 3.4 ppl better than the previous best of Transformer-XL of comparable size).
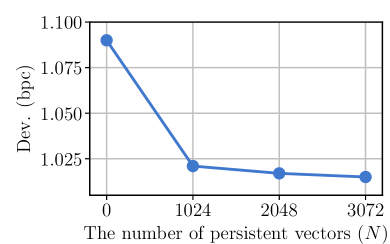
- Ablation studies show persistent vectors are essential (N around 1024 suffices) and that joint all-attention over context and persistent vectors is superior to alternative integration schemes like separate attention.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。