[論文レビュー] Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions
本論文は、実世界のオンライン意思決定タスク(WebShopとALFWorld)においてAuto-GPT風エージェントをベンチマークし、外部専門モデルの提案を注入して性能を向上させるAdditional Opinionsアルゴリズムを紹介します。特にGPT-4で効果的。
Auto-GPT is an autonomous agent that leverages recent advancements in adapting Large Language Models (LLMs) for decision-making tasks. While there has been a growing interest in Auto-GPT stypled agents, questions remain regarding the effectiveness and flexibility of Auto-GPT in solving real-world decision-making tasks. Its limited capability for real-world engagement and the absence of benchmarks contribute to these uncertainties. In this paper, we present a comprehensive benchmark study of Auto-GPT styled agents in decision-making tasks that simulate real-world scenarios. Our aim is to gain deeper insights into this problem and understand the adaptability of GPT-based agents. We compare the performance of popular LLMs such as GPT-4, GPT-3.5, Claude, and Vicuna in Auto-GPT styled decision-making tasks. Furthermore, we introduce the Additional Opinions algorithm, an easy and effective method that incorporates supervised/imitation-based learners into the Auto-GPT scheme. This approach enables lightweight supervised learning without requiring fine-tuning of the foundational LLMs. We demonstrate through careful baseline comparisons and ablation studies that the Additional Opinions algorithm significantly enhances performance in online decision-making benchmarks, including WebShop and ALFWorld.
研究の動機と目的
- Auto-GPT風エージェントが実世界のオンライン意思決定タスクでどのように機能するかを調査する。
- Auto-GPT設定における複数のLLM(GPT-4、GPT-3.5、Claude、Vicuna)を比較する。
- 外部の専門モデルを意見提供者として利用するAdditional Opinionsアルゴリズムを提案し、評価する。
- アブレーションおよびベースライン研究を通じて、軽量な監督が微調整なしで性能を向上させるかを実証する。
提案手法
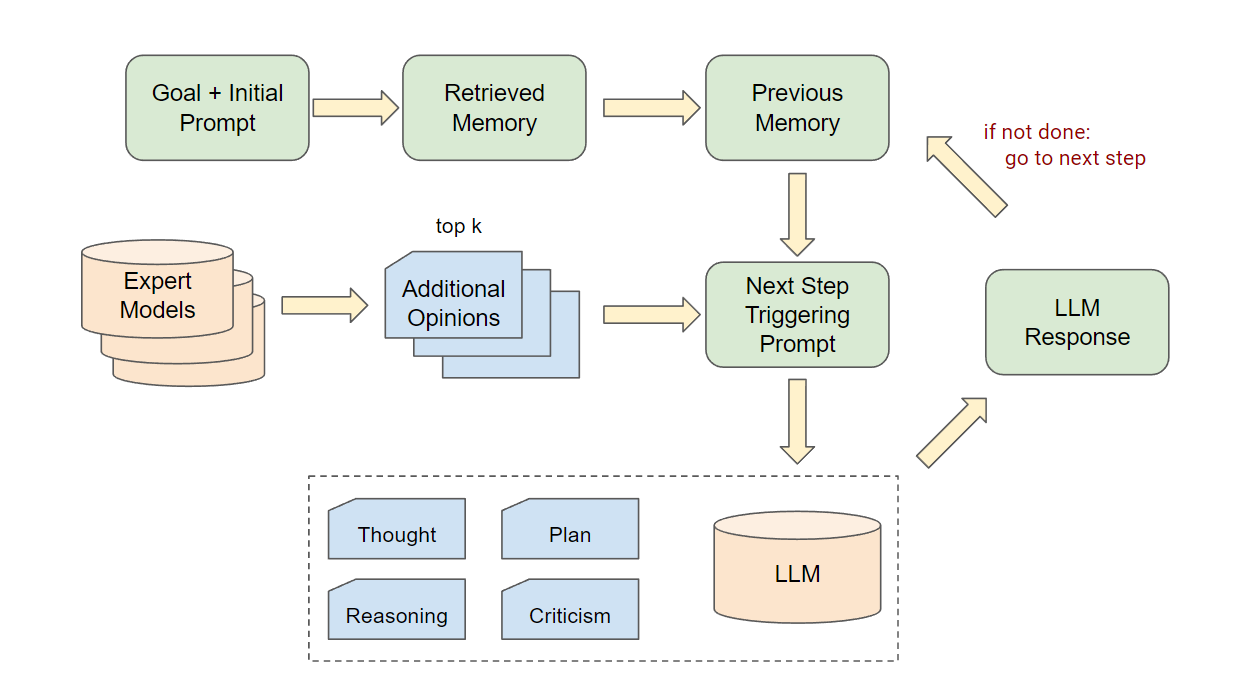
- 最小限のプロンプト改善でAuto-GPTを2つのオンライン意思決定タスクに適応させる。
- 行動をツールとして表現し、1–3のファウショットツールデモンストレーションを提供してインコンテキスト学習を活用する。
- 外部専門モデルからtop-kの意見をサンプリングし、それらを参照としてプロンプト文脈に注入してAdditional Opinionsを導入する。
- WebShopとALFWorldを横断して、模倣学習ベースラインおよびさまざまなLLMsと比較評価する。
- ランダム性を抑えるため低い温度を使用し、IL+Auto-GPT系で分散を制御するために複数回実行する。)
実験結果
リサーチクエスチョン
- RQ1Auto-GPT風エージェントは現実世界の環境に似たオンライン意思決定タスクに効果的に適応できるか。
- RQ2WebShopとALFWorldにおけるAuto-GPT設定で、どのLLM(GPT-4、GPT-3.5、Claude、Vicuna)が最も高い性能を発揮するか。
- RQ3外部の専門モデルからのAdditional Opinionsを取り入れることで、基盤となるLLMsを微調整せずに意思決定の性能を向上させるか。
- RQ4単一の追加意見と複数の追加意見の性能への相対的影響はどの程度か、タスクとモデルによってどう異なるか。
主な発見
| モデル | 成功率 | 報酬 | 精度 | 購入率 | モデル | 成功率 | 報酬 | 精度 | 完了率 |
|---|---|---|---|---|---|---|---|---|---|
| Rule | 0.060 | 44.589 | 0.060 | 1.000 | |||||
| IL w/o. Image | 0.213 | 56.056 | 0.213 | 1.000 | |||||
| IL | 0.227 | 57.689 | 0.227 | 1.000 | |||||
| Auto-GPT(Claude) | 0.140 | 47.617 | 0.146 | 0.960 | |||||
| Auto-GPT(Claude) + IL | 0.240 | 48.600 | 0.270 | 0.890 | |||||
| Auto-GPT(Claude) + IL(top5) | 0.220 | 52.010 | 0.229 | 0.960 | |||||
| Auto-GPT(GPT3.5) | 0.120 | 43.833 | 0.140 | 0.860 | |||||
| Auto-GPT(GPT3.5) + IL | 0.200 | 47.717 | 0.241 | 0.830 | |||||
| Auto-GPT(GPT3.5) + IL(top5) | 0.230 | 52.827 | 0.279 | 0.820 | |||||
| AutoGPT(GPT3.5) + Random | 0.060 | 22.333 | 0.136 | 0.440 | |||||
| Auto-GPT(GPT4) | 0.240 | 46.133 | 0.353 | 0.680 | |||||
| Auto-GPT(GPT4) + IL | 0.300 | 56.233 | 0.361 | 0.830 | |||||
| Auto-GPT(GPT4) + IL(top5) | 0.320 | 61.550 | 0.372 | 0.860 | |||||
| Auto-GPT(Vicuna) | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| Auto-GPT(Vicuna) (duplicate) | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| IL w/o. Beam Search | 0.179 | 24 | 1.000 | 0.179 | |||||
| IL | 0.306 | 41 | 1.000 | 0.441 | |||||
| Auto-GPT(Claude) | 0.082 | 11 | 0.104 | 0.791 | |||||
| Auto-GPT(Claude) + IL | 0.090 | 12 | 0.130 | 0.687 | |||||
| Auto-GPT(GPT3.5) | 0.075 | 10 | 0.078 | 0.866 | |||||
| Auto-GPT(GPT3.5) + IL | 0.030 | 4 | 0.048 | 0.470 | |||||
| Auto-GPT(GPT4) | 0.485 | 65 | 0.628 | 0.582 | |||||
| Auto-GPT(GPT4) + IL | 0.515 | 69 | 0.789 | 0.530 | |||||
| Auto-GPT(Vicuna) | 0.000 | 0 | 0.000 | 0.000 |
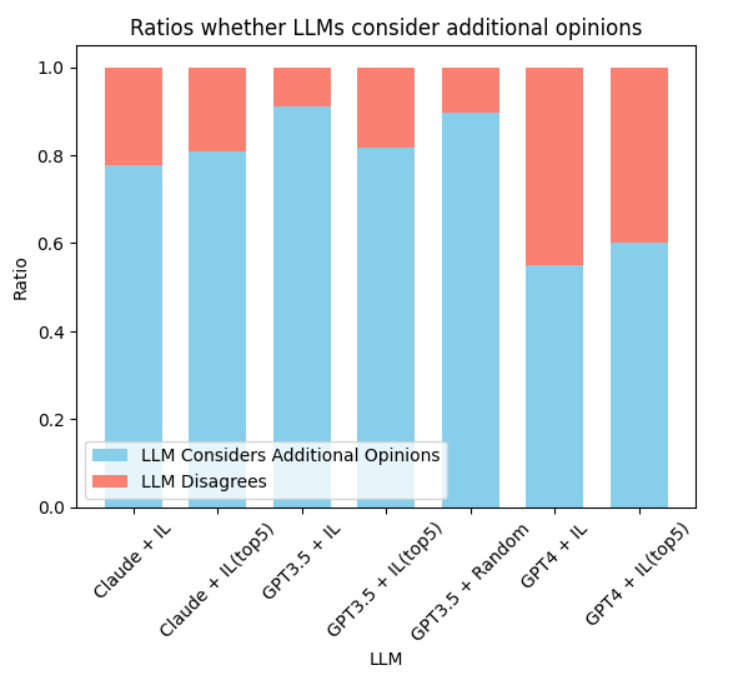
- GPT-4ベースのAuto-GPT系が、2つのタスクのうち双方でテストされたモデルの中で最高の性能を達成。
- 専門モデルからtop-kのAdditional Opinionsを提供することで性能が向上し、GPT-4は複数の意見から顕著に恩恵を受ける。
- WebShopでは、Additional Opinionsを用いたGPT-4が多くのベースラインより高い成功率、精度、報酬を達成。
- ALFWorldでは、GPT-4が模倣学習のベースラインを大幅に上回り、ILにおけるビーム探索の有無が結果に影響を与える。
- ClaudeとGPT-3.5はAuto-GPT設定で概ねGPT-4を下回るが、レイテンシのトレードオフが存在。
- VicunaベースのAuto-GPTは性能が低い、あるいは整形された応答を生成できない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。