[論文レビュー] Automated Annotation with Generative AI Requires Validation
本論文は、LLMによる自動注釈を人間のラベルと比較して検証すべきだと主張し、5段階の作業フローを提案し、27のタスクにおけるさまざまなLLMの性能を示す。全体的には有望だが、タスク依存の信頼性。
Generative large language models (LLMs) can be a powerful tool for augmenting text annotation procedures, but their performance varies across annotation tasks due to prompt quality, text data idiosyncrasies, and conceptual difficulty. Because these challenges will persist even as LLM technology improves, we argue that any automated annotation process using an LLM must validate the LLM's performance against labels generated by humans. To this end, we outline a workflow to harness the annotation potential of LLMs in a principled, efficient way. Using GPT-4, we validate this approach by replicating 27 annotation tasks across 11 datasets from recent social science articles in high-impact journals. We find that LLM performance for text annotation is promising but highly contingent on both the dataset and the type of annotation task, which reinforces the necessity to validate on a task-by-task basis. We make available easy-to-use software designed to implement our workflow and streamline the deployment of LLMs for automated annotation.
研究の動機と目的
- LLMベースの注釈には、専門家の人間ラベルに対するタスク特異的な検証が必要であることを示す。
- 人間の判断を前面に出しつつ、LLMsでテキスト注釈を補強するための原理的で効率的なワークフローを開発する。
- 多様で非公開の社会科学データセット全体でLLMの性能を評価し、ユースケースと限界を特定する。
- ワークフローを実装し、注釈の一貫性を測るオープンソースソフトウェアを提供する。
提案手法
- タスク固有のコードブックを用いたLLM補強注釈の5段階ワークフローを提案する。
- 二名の専門家とLLMが同じコードブックを用いて共有データのサブセットを注釈する。
- 保持サンプルにおける人間ラベルと比較して、精度、適合率、再現率、F1を評価する。
- 誤分類に対処するために、人間が介在する形でコードブックを反復的に更新する。
- 残りの人間ラベル付きサンプルでLLMの性能をテストし、自動注釈の実現可能性を判断する。
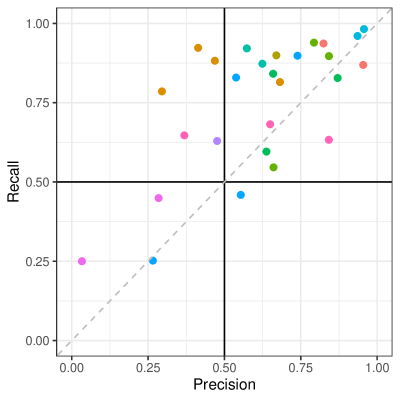
実験結果
リサーチクエスチョン
- RQ1専門家ラベルで検証した場合、LLMsは多様な社会科学タスクで信頼できるテキスト注釈を実現できるか?
- RQ2コードブック( prompting)の洗練がLLMの分類性能にどう影響するか?
- RQ3タスク性能が変動する中で、注釗 workflows にLLMsを組み込む実用的なユースケースは何か?
- RQ4エッジケースを特定し品質を確保するのに役立つ指標や概念(一貫性スコア)は何か?
主な発見
| Metric | Minimum | 25th percentile | Mean | Median | 75th percentile | Maximum |
|---|---|---|---|---|---|---|
| Accuracy | 0.674 | 0.808 | 0.855 | 0.85 | 0.905 | 0.981 |
| Precision | 0.033 | 0.472 | 0.615 | 0.650 | 0.809 | 0.957 |
| Recall | 0.25 | 0.631 | 0.749 | 0.829 | 0.899 | 0.982 |
| F1 | 0.059 | 0.557 | 0.660 | 0.707 | 0.830 | 0.969 |
- LLM注釈は27タスクで中央値F1が0.707を達成するが、性能はタスク依存性が高い。
- 27タスクのうち9件で適合率または再現率が0.5未満で、顕著なエッジケースと非一般化可能な結果を示している。
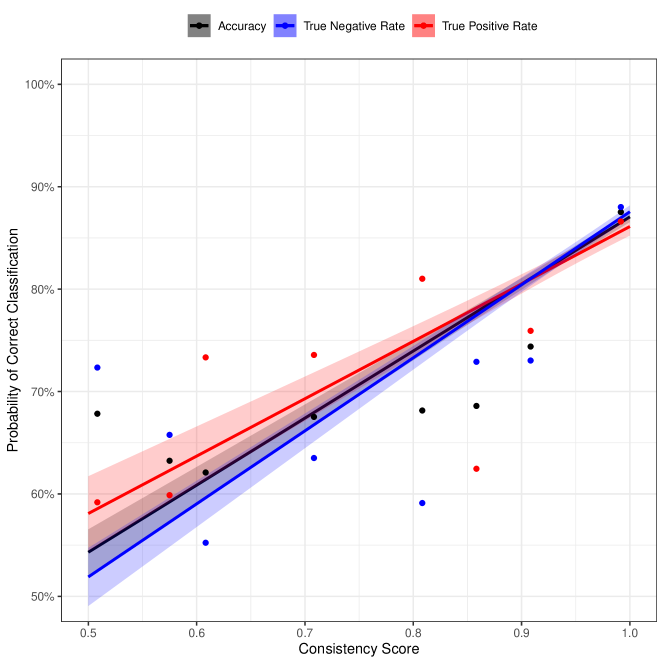
- 一貫性スコアは正確さと真陽性/真陰性率と相関し、難易度の高いサンプルを特定するのに役立つ。
- コードブックの更新は控えめな改善を生み出し、プロンプト設計だけでは性能向上の強力な手段とはならない。
- 性能とリソース制約に応じて柔軟にLLMsを統合できる4つのユースケース。
- 本ワークフローと同梱のオープンソースツールは、人間の介在による検証を組み込んだLLM補強注釈の実装を合理化する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。